
For every travel service provider, the search engine is a key, even critical, functionality of their tourism service. Modern travelers expect precise and quick results that meet their individual requirements, such as budget or preferences regarding location, accommodation type, and activities. Therefore, proper search engine operation is fundamental for ensuring high-quality customer service and satisfaction with the travel service.
But have you ever wondered how a travel search engine finds the perfect vacation among millions of possible combinations in a fraction of a second? In this article, we’ll try to answer this question by showing how search technologies evolved from simple SQL queries to advanced systems using Big Data. We’ll use the real example of our Qtravel Search travel engine to illustrate better how modern system architecture handles processing enormous amounts of data and providing lightning-fast search results.
Evolution of Search Systems
For many years, search processes in web applications relied on SQL queries executed directly in relational databases. In many cases, such a solution could indeed be sufficient, for example, with a simple data structure or relatively few records in the table where we performed the search. Relational databases worked best when searching was based on strictly defined criteria – in the case of travel offers, these were usually categories such as destination country, location, or departure date.
Qtravel Search – Classic Search
Pseudo code for SQL query with basic filters in classic search

As data volumes grew and structure became more complex, searching in relational databases became increasingly complicated and less efficient. There was also growing demand for other functionalities that RDBMS databases didn’t provide—this primarily concerned full-text search, which became the default search method in e-commerce and news websites.
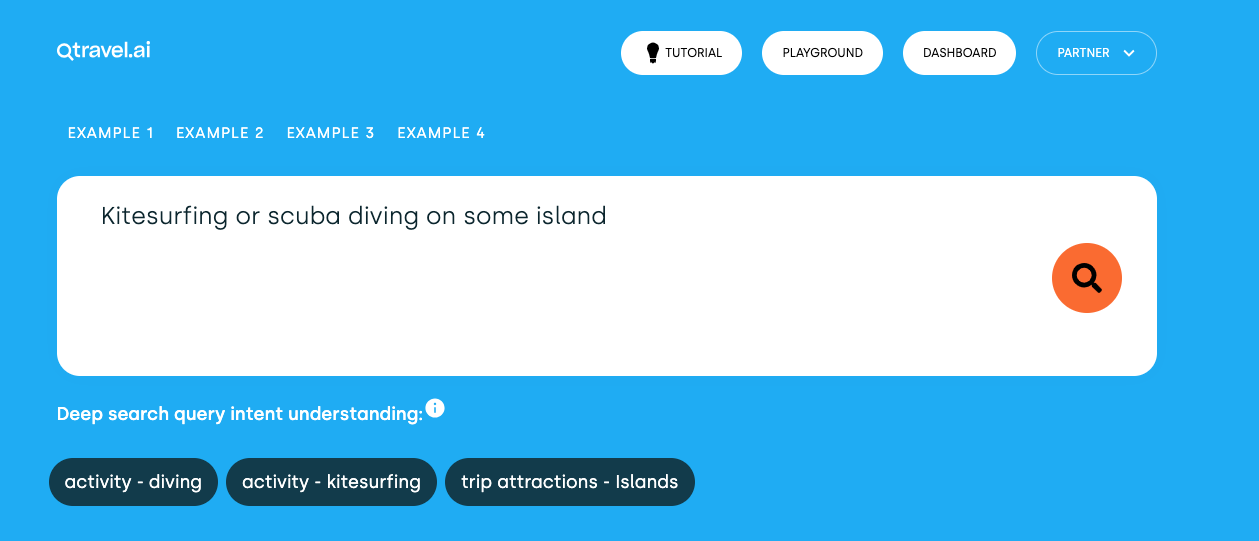
Analysis of user preferences, as well as user reviews, which play a major role when customers search for suitable offers, require systems to handle more complex queries and process huge amounts of data in real-time.
Therefore, a natural step in search system development was to separate the search process into a dedicated search system specialized in text searching through large numbers of records, known as search engines. You can find a list of the most popular search engines on the DB-Engines website.
How Do Search Engines Work?
Search engines work by creating indexes that enable quick and efficient searching through large data sets. This process involves analyzing documents and creating a data structure that enables quick access to information based on queries. Search engines use techniques such as tokenization, stemming, and filtering to transform text into an optimal form for searching. These processes enable quick searching, sorting, and filtering of data according to specific criteria.
At Qtravel.ai, we focus on Apache Solr and ElasticSearch, which are based on the Apache Lucene library and enable full-text search and data analysis. Their operation can be divided into key processes: indexing and searching.
Data Indexing
Data indexing is creating a “map” that allows quick information finding. Just as an index in a book helps find a topic on a specific page, a Solr index enables efficient searching through large data sets. Before indexing begins, data must be properly prepared and configured. Solr/ElasticSearch require a schema that defines which fields should be stored, their types (e.g., text, number, date), and what operations they can perform.
Once the data matches the schema, the index creation process can begin. This can be done in several ways, for example, by sending data to Solr using simple commands or automation tools. Solr processes the data, analyzing text, breaking it into smaller fragments (e.g., words), and creating an index that enables quick searching.
Data Searching
Data searching involves searching through the previously created index to find documents that best match the query. This process includes analyzing the query, matching results based on matches and rankings, and optimizing results to ensure the most relevant results.
Delivering data to the search engine index can be a very complex process. It often requires building a separate data processing system that collects data from various sources and then transforms it into a format supported by the mentioned search engines. Later in the article, we’ll discuss the architecture of such a system that has been adapted to process large sets of tourism data.

Tourism Data: What Elements Does It Include?
Tourism is one of the industries where data plays a key role. Each travel offer is a complex information set that must be precisely processed, managed, and presented to the customer. Unlike typical e-commerce, where products are relatively simple to describe (e.g., a shirt in different sizes and colors), a travel offer is a complex data set requiring advanced management. This data includes information about hotels, rooms, flights, meals, configurations of adults and children in rooms, and most importantly, prices for such complex travel offers.
Example data structure in tourism:
What Makes Travel Offers Complex?
To illustrate the complexity, let’s look at one travel offer for a selected hotel, which includes the following variables:
- 3 meal types: breakfast, HB, All Inclusive
- 5 airports (i.e., departure possible from 5 different locations)
- Length of stay: choice between 3 and 6 days
- 3 room types (e.g., standard, sea view, apartment)
- 5 different person configurations (e.g., 1 adult, 2 adults, 2 adults + 1 child, etc.)
Calculating Possible Combinations
For a single offer, the number of possible configurations comes from multiplying the number of available options:
Number of combinations = 3 (meals) × 5 (airports) × 2 (length of stay) × 3 (rooms) × 5 (configurations) = 450
At first glance, this doesn’t look too bad, even when compared to a typical e-commerce product (T-shirt), where you might get up to 150 different options for one product:
Number of combinations = 10 (colors) × 5 (sizes) × 3 (materials) = 150
However, the challenge in tourism is that in addition to various offer configurations, you also need to consider dates and availability periods, which significantly increases the number of possible combinations.
Let’s assume we have 450 possible combinations regarding food, airports, duration, rooms and number of people.
We also need to consider flight frequency:
Number of combinations per year = 450 (combinations) × 365/3 (departures every 3 days) = 54,750
If we now multiply the number of all combinations by the number of offers:
Total number of combinations = 54,750 (combinations per year) × 1000 (number of offers) = 54,750,000
Moreover, travel agencies often want to show offers for upcoming seasons, which can increase the period for which combinations are created from one year to, for example, two years.
Based on this information, it’s clear that a travel offer is much more complex than a typical e-commerce product. Such many variables and possible combinations mean adapting offers to customer needs, which requires advanced data management systems and efficient processing.
Tourism Data Processing Architecture
In tourism, we deal with enormous amounts of data – imagine millions of travel offer combinations that change constantly. Additionally, customers look for travel offers that meet their specific criteria, such as departure date or planned budget. This requires fast, efficient processing and analysis of information, which is very difficult in traditional search systems based on relational databases.
Due to dynamically changing prices and date availability in tourism, instead of traditional solutions, at Qtravel.ai we implemented a system based on technologies typical for processing large data sets (Big Data), such as:
- Apache Hadoop: a system that allows us to store large amounts of data by distributing it across different servers. This enables even enormous data sets to be analyzed quickly.
- Apache Spark: a tool that enables fast data processing. Unlike traditional systems, Spark processes data in memory, which significantly speeds up analysis.
- Apache Airflow: a tool that manages and automates our data processing tasks. Thanks to this, tourism data processing processes are organized, and results are delivered on time.
Processing Concepts
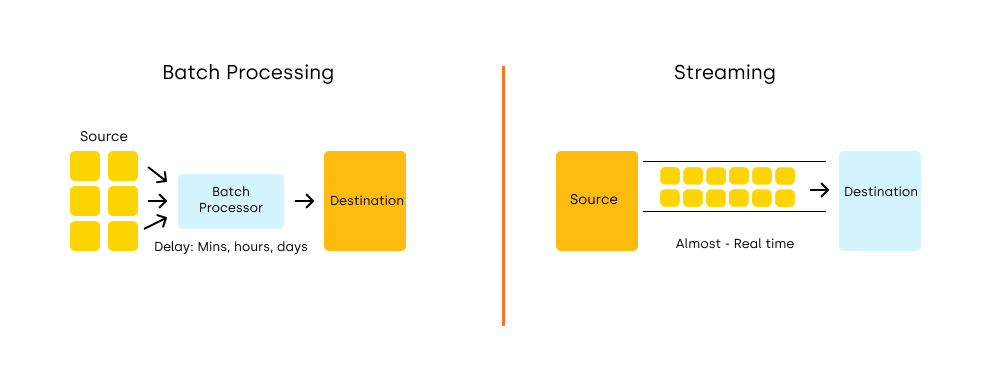
Batch Processing
Batch processing involves analyzing large sets of data collected over longer periods of time. Data is collected and then processed in batches, which is efficient when there’s no need for immediate analysis. This approach is widely used in processes that require high computational power, such as generating reports, historical analyses, or statistical calculations. Apache Spark is well-suited for batch processing thanks to its ability to process data in parallel across a cluster, which speeds up the analysis of large amounts of information.
Stream Processing
Stream processing focuses on analyzing data as it arrives, allowing immediate reaction to changing conditions, such as offer availability, tickets, prices, or other dynamic information (e.g., flight times). It’s ideal when access to real-time or near real-time information is crucial, such as event monitoring, dynamic pricing, or financial transaction management. Apache Spark Streaming enables stream data processing, delivering results almost immediately after they appear.
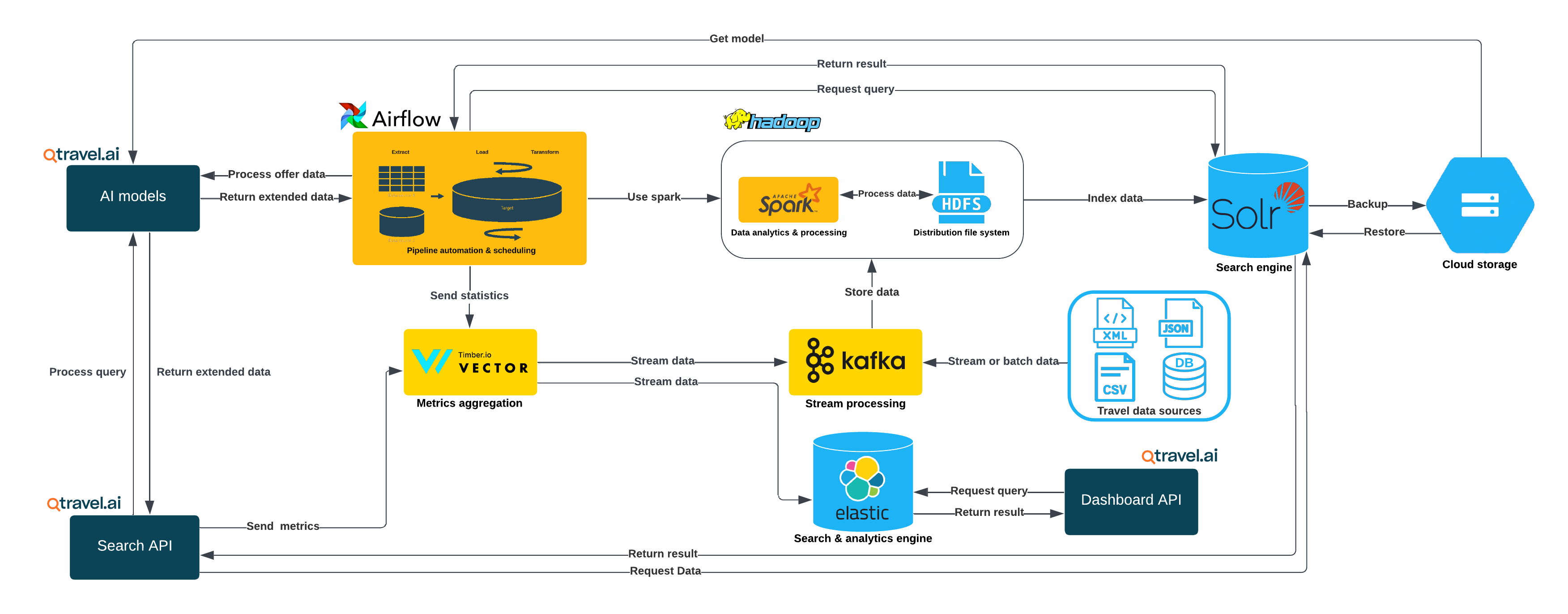
Conclusion
Choosing the right tourism data processing architecture is key to ensuring performance and scalability. Thanks to their capabilities, Apache Hadoop and Apache Spark provide a very good solution for handling both batch and stream processing, meeting the needs of modern tourism applications.
If you want to learn more about this topic, we recommend checking out these knowledge sources:
- DB-Engines Ranking
- Apache Spark™ – Unified Engine for large-scale data analytics
- Apache Hadoop
- Apache Airflow
- Apache Solr Reference Guide :: Apache Solr Reference Guide
- Batch vs Stream Processing: When to Use Each and Why It Matters
If you want to test our search engine and see how it works in practice, check out the demo of this solution.