
Uczenie maszynowe to termin, z którym z pewnością niejednokrotnie się już spotkaliście. Ale czy wiecie, co dokładnie się za nim kryje i czym różni się od innych podobnych pojęć, takich jak sztuczna inteligencja czy głębokie uczenie? W tym artykule postaramy się w prosty i zrozumiały sposób przybliżyć Wam tę technologię, a do tego wyjaśnić, jak działają poszczególne techniki uczenia maszynowego.
Zaczynamy!
Czym jest uczenie maszynowe?
Uczenie maszynowe (ang. Machine Learning) to poddziedzina sztucznej inteligencji, który jak sama nazwa wskazuje – koncentruje się na nauczaniu maszyn, a dokładniej – komputerów określonych czynności w sposób podobny do tego, jak uczą się ludzie.
Technologia ta polega na dostarczaniu wiedzy komputerom w postaci danych, obserwacji i interakcji ze światem, a następnie odnajdywaniu przez nie określonych wzorców i cech. W tym celu systemy uczenia maszynowego mogą wykorzystywać szereg algorytmów, takich jak sieci neuronowe czy klasteryzację (patrz: słowniczek).
Co ważne, proces uczenia maszynowego algorytmów polega na zdolności komputerów do automatycznego znajdowania odpowiednich wzorców i korelacji w przetwarzanych danych oraz podejmowania najlepszych decyzji na tej podstawie.
Jaka jest różnica pomiędzy sztuczną inteligencją a uczeniem maszynowym?
Uczenie maszynowe często jest błędnie utożsamiane ze sztuczną inteligencją. A jaka jest różnica? Czas rozwiać tę zagadkę.
W dużym uproszczeniu, sztuczna inteligencja (ang. Artificial Intelligence, AI) to obszerna dziedzina, która zajmuje się tworzeniem maszyn zdolnych do wykonywania złożonych zadań, które do tej pory wymagały ludzkiej inteligencji (m.in. rozumienie języka czy rozpoznawanie obrazów).
Uczenie maszynowe natomiast to poddziedzina sztucznej inteligencji, który skupia się na rozwijaniu algorytmów i modeli, które uczą się na podstawie danych i doświadczeń.
Aby jeszcze lepiej zobrazować tę różnicę, możemy porównać to do różnicy między butami a kozakami. Sztuczna inteligencja to cała kategoria – podobnie jak buty. Natomiast uczenie maszynowe to konkretny rodzaj, taki jak kozaki wśród butów. Wszystkie kozaki są butami, ale nie każdy but jest kozakiem. Analogicznie, wszystkie technologie oparte na uczeniu maszynowym są określane jako sztuczna inteligencja, ale nie wszystkie formy sztucznej inteligencji opierają się na uczeniu maszynowym.
Warto przy tym pamiętać, że uczenie maszynowe posiada również swoje poddziedziny, takie jak głębokie uczenie. Aby lepiej zrozumieć tę zależność, warto zapoznać się z ilustracją poniżej:
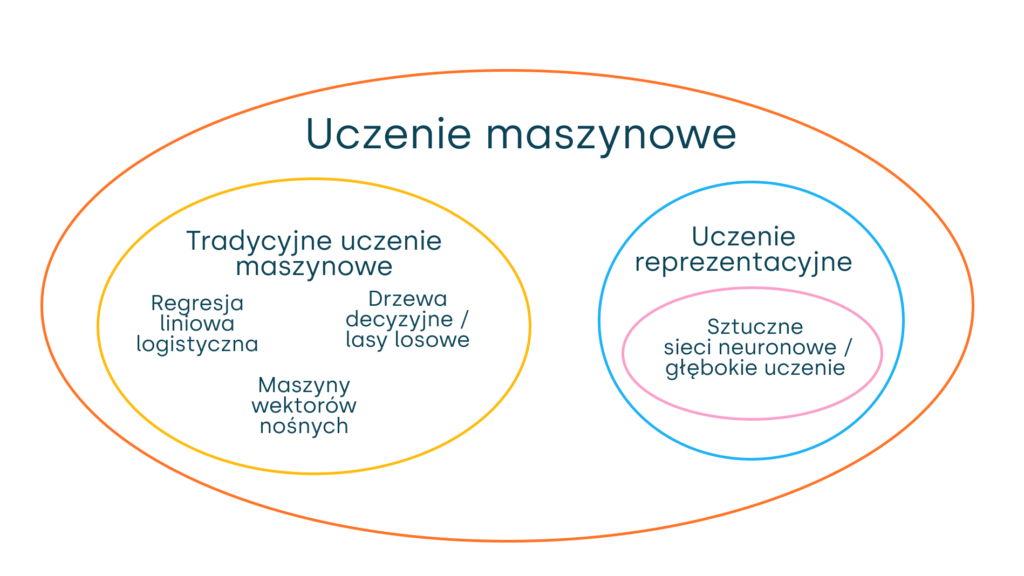
Jak działa uczenie maszynowe?
Proces uczenia maszynowego składa się z kilku podstawowych kroków, które można łatwo zilustrować:
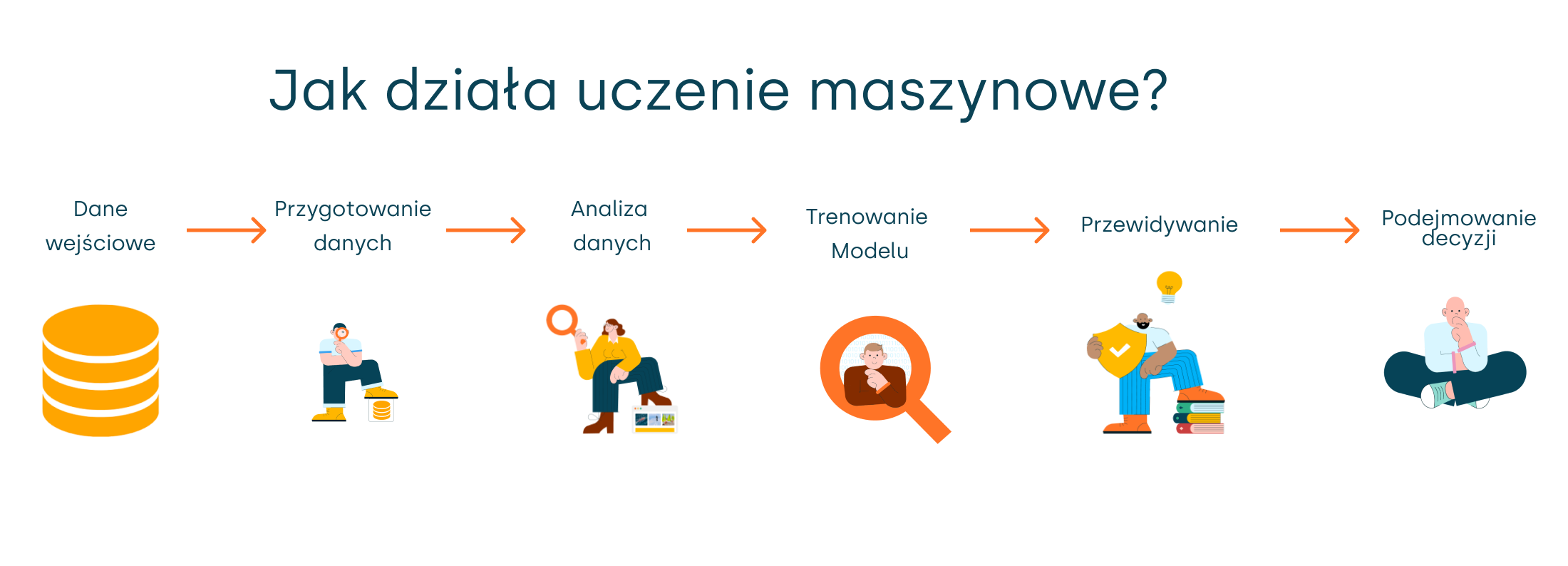
- Dane wejściowe: Wszystko zaczyna się od gromadzenia danych. Mogą to być zdjęcia, teksty, dźwięki, dane numeryczne itp.
- Przygotowanie danych: Dane są następnie przetwarzane i oczyszczane, aby były jak najbardziej precyzyjne. W tym etapie usuwane są wszelkie nieścisłości, błędy czy brakujące wartości. Jest to krok opcjonalny, ale zalecany, aby otrzymać lepsze wyniki.
- Analiza danych: Na tym etapie model uczenia maszynowego próbuje zrozumieć strukturę danych oraz zależności między różnymi cechami.
- Trenowanie Modelu: Model, bazując na analizie, stara się znaleźć w danych ukryte wzorce i zależności.
- Przewidywanie: Na podstawie znalezionych wzorców model jest w stanie dokonać przewidywań dla nowych, wcześniej niewidzianych danych.
- Podejmowanie decyzji: Na podstawie dokonanych przewidywań, system podejmuje konkretne decyzje i działania. Na przykład, określa dany e-mail jest spamem czy wartościową wiadomością i na tej podstawie umieszcza go w odpowiednim folderze.
Techniki uczenia maszynowego
Szczegóły dotyczące tego, jak dokładnie wygląda proces uczenia maszynowego zależy od techniki, którą się posługujemy. Poniżej opisaliśmy 4 podstawowe metody.
Uczenie nadzorowane
Uczenie nadzorowane (ang. supervised learning) to metoda polegająca na uczeniu modelu odwzorowania pomiędzy danymi wejściowymi a oczekiwanym wyjściem na podstawie znanych etykiet (zapewnionych przez człowieka).
Przykładowo, jeśli chcesz nauczyć system rozpoznawania czy dany owoc to jabłko czy truskawka, Twój zestaw danych treningowych może zawierać zdjęcia owoców (dane wejściowe) oraz informację, czy dany obraz przedstawia jabłko czy truskawkę (etykieta). Następnie, system analizuje dane i uczy się relacji między danymi wejściowymi a wyjściowymi, aby w przyszłości samodzielnie rozpoznać te owoce.
Przykłady zastosowania uczenia nadzorowanego to m.in. systemy do wykrywania spamu czy wspomniane wyżej rozpoznawanie obrazów.
Warto też dodać, że jednym z rodzajów uczenia nadzorowanego jest regresja. Jest to technika analizy statystycznej używana do przewidywania wartości liczbowych. Jej celem jest znalezienie zależności pomiędzy jedną lub wieloma zmiennymi niezależnymi, a zmienną zależną.
Przykłady zastosowania regresji to prognozowanie cen akcji firm lub cen sprzedaży produktów.
Uczenie nienadzorowane
Uczenie nienadzorowane (ang. unsupervised learning) polega na tym, że model samodzielne analizuje zestaw danych wejściowych nie znając etykiet.
W przeciwieństwie do uczenia nadzorowanego, w tym przypadku algorytm nie posiada wcześniej określonych odpowiedzi. Zamiast tego, stara się zidentyfikować ukryte wzorce i struktury w danych i szukać korelacji między nimi.
Analogicznie do przykładu z owocami, jeśli dostarczymy systemowi zestaw zdjęć różnych owoców, bez dodatkowych informacji, jaki owoc znajduje się na określonym zdjęciu, system może samodzielnie podzielić je na grupy bazując na podobieństwach, choć nie będzie wiedział, że jedna z grup to jabłka, a inna to truskawki.
Główną ideą uczenia nienadzorowanego jest eksploracja danych w celu znalezienia ukrytych wzorców lub struktur. Nie wymaga ono „nadzoru” w tradycyjnym sensie, ale może wymagać dodatkowej analizy ze strony człowieka w celu interpretacji wyników.
Przykłady zastosowania uczenia nienadzorowanego to m.in. klastrowanie grup klientów, wykrywanie anomalii, grupowanie tematów artykułów.
Uczenie częściowo nadzorowane
Uczenie częściowo nadzorowane (ang. semi-supervised learning) stanowi kompromis między uczeniem nadzorowanym a nienadzorowanym. To podejście polega na wykorzystaniu stosunkowo niewielkiej liczby etykietowanych danych w połączeniu z dużą ilością danych bez etykiet. Jego głównym celem jest wykorzystanie etykietowanych próbek do pomocy w zrozumieniu struktury ogólnej nieetykietowanego zestawu danych.
Główną zaletą tego podejścia jest zdolność do tworzenia dokładnych modeli przy znacznie niższych kosztach etykietowania danych. Dzięki temu uczenie częściowo nadzorowane jest szczególnie przydatne w sytuacjach, gdzie ręczne etykietowanie danych jest czasochłonne lub kosztowne, ale dostępna jest duża ilość nieetykietowanych danych.
Uczenie częściowo nadzorowane znajduje zastosowanie w dziedzinach takich jak analiza mowy, przetwarzanie języka naturalnego czy wykrywanie oszustw.
Uczenie ze wzmocnieniem
Uczenie ze wzmocnieniem (ang. reinforcement learning) to technika, w której maszyna uczy się poprzez interakcje ze środowiskiem. W odróżnieniu od uczenia nadzorowanego, gdzie maszyna jest instruowana za pomocą konkretnych odpowiedzi, tutaj system uczy się poprzez próby i błędy, a nie przez analizę określonego zestawu danych treningowych.
W uczeniu ze wzmocnieniem agent (model/algorytm) wykonuje akcje w środowisku, za które otrzymuje nagrody (albo kary). Polega to na odkrywaniu, które akcje prowadzą do uzyskania największej nagrody w danym stanie środowiska. Kluczowe jest więc odpowiednie zdefiniowanie „nagrody”, będącej wartością numeryczną, która mierzy jak dobrze system radzi sobie w osiągnięciu swojego celu.
Dobrym przykładem jest nauka robota, jak chodzić. Robot nie otrzymuje instrukcji dotyczących tego, jak dokładnie poruszać każdą częścią ciała. Zamiast tego dostaje informację zwrotną w postaci “nagrody”, gdy porusza się poprawnie, i “kary”, gdy upada. Poprzez wielokrotne próby i błędy, robot optymalizuje swoje ruchy, by osiągnąć jak najlepsze wyniki.
Innym ciekawym przykładem jest nauka gry w szachy. W tym przypadku, akcje to wykonywane przez model ruchy, środowisko to plansza i ruchy przeciwnika, a końcowa nagroda to wygrana/przegrana.
Zastosowania uczenia ze wzmocnieniem obejmują takie obszary, jak autonomiczne pojazdy uczące się unikać przeszkód czy algorytmy handlowe dokonujące inwestycji na giełdzie w celu maksymalizacji zysków lub minimalizacji strat. Ten rodzaj uczenia maszynowego ma też swoje szczególne miejsce w grach. Mowa tu chociażby o wspomnianej wyżej grze w szachy, a także tytułach takich jak Go czy Starcraft, które bardzo przyczyniły się do rozwoju reinforcement learning. Co ciekawe, nawet tworzenie asystentów takich jak ChatGPT opiera się m.in na wykorzystaniu uczenia ze wzmocnieniem.
Słowniczek najważniejszych pojęć związanych z uczeniem maszynowym
- Sieci neuronowe (Neural Networks): Model oparty na działaniu ludzkiego mózgu, skupiający się na rozpoznawaniu wzorców. Używany w tłumaczeniu języka, rozpoznawaniu obrazów i mowy.
- Głębokie sieci neuronowe (Deep Neural Networks): To specyficzny rodzaj sieci neuronowych, które mają wiele warstw między warstwą wejściową a wyjściową. Każda warstwa składa się z neuronów, które przetwarzają dane i przekazują je do kolejnej warstwy. Wzrost liczby warstw pozwala modelowi uczyć się bardziej złożonych, abstrakcyjnych cech występujących w danych.
- Regresja liniowa (Linear Regression): Algorytm służący do określenia ciągłej wartości liczbowej na podstawie liniowej kombinacji innych wartości. Przykładem może być przewidzenie ceny wynajmu mieszkania na podstawie pożądanego metrażu, liczby pokoi, dzielnicy itp.
- Regresja logistyczna (Logistic Regression): Model używany do przewidywań kategorii, na przykład odpowiedzi „tak/nie”. Zastosowanie to m.in. klasyfikowanie spamu.
- Klasteryzacja (Clustering): Algorytm grupujący dane w oparciu o podobieństwa. Pozwala na wykrycie wzorców, które mogłyby zostać przeoczone przez ludzi.
- Drzewa decyzyjne (Decision Trees): Reprezentują decyzje i ich możliwe konsekwencje w formie drzewa. Mogą być używane do prognozowania wartości lub klasyfikowania danych. Ich dużą zaletą jest łatwa interpretowalność decyzji i ekstrakcji wiedzy z modelu.
- Lasy losowe (Random Forests): Kombinacja wielu drzew decyzyjnych w celu poprawy dokładności prognozy i zapobiegania nadmiernemu dopasowaniu.
- Głębokie uczenie (Deep Learning): Poddziedzina uczenia maszynowego, która polega na korzystaniu z głębokich sieci neuronowych w celu wykonywania złożonych zadań. Dzięki swej głębokości i złożoności jest zdolne do analizowania skomplikowanych wzorców w dużych zbiorach danych. Znajduje zastosowanie w zaawansowanym rozpoznawaniu obrazów, przetwarzaniu języka naturalnego oraz analizie dźwięku.
Podsumowanie
To już trzeci z serii artykułów wyjaśniających najważniejsze pojęcia związane z AI. Jeśli jeszcze ich nie czytaliście, a chcecie usystematyzować swoją wiedzę na temat sztucznej inteligencji, Big Data lub sieci neuronowych – polecamy zapoznać się z tymi wpisami.
A jeśli macie jakiekolwiek pytania na temat uczenia maszynowego – standardowo zapraszamy do kontaktu 🙂