Nasza wyszukiwarka Qtravel Search udostępnia wszystkie funkcjonalności wyszukiwania i prezentacji ofert turystycznych w postaci interfejsu programowania aplikacji API opartego na języku zapytań GraphQL. Technologia ta zapewnia programistom zaawansowany zestaw narzędzi do tworzenia najwyższej jakości doświadczeń związanych z wyszukiwaniem w branży turystycznej.
W niniejszym artykule przyjrzymy się, czym jest GraphQL, dlaczego zdobył dużą popularność w środowisku informatycznym, czym się różni od interfejsów REST API i jaką ma nad nimi przewagę. Pokażemy też, jak korzystać z GraphQL na przykładzie API naszej wyszukiwarki Qtravel Search.
Czym jest GraphQL?
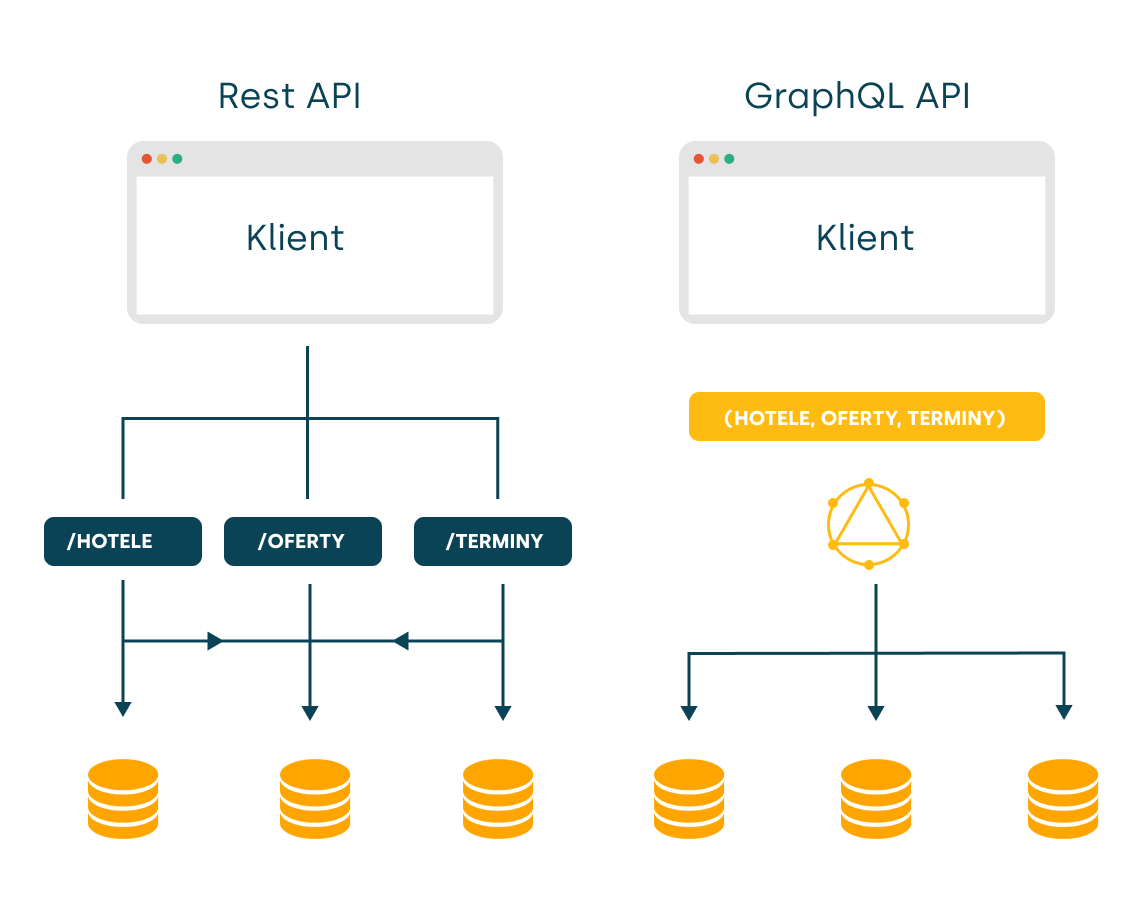
GraphQL to język zapytań i manipulacji danych oraz środowisko uruchomieniowe po stronie serwera dla interfejsów programowania aplikacji (APIs). GraphQL, podobnie jak standard XML czy SQL posiada formalną specyfikację, która opisuje język i gramatykę używane do definiowania zapytań, system typów i silnik wykonawczy. Jest to jedna z najważniejszych cech odróżniających GraphQL od powszechnie używanego interfejsu komunikacji między aplikacjami w architekturze mikrousług – REST API, który formalnej specyfikacji nie posiada. Zamiast wielu endpointów, które zwracają oddzielne dane, serwer GraphQL udostępnia pojedynczy endpoint /graphql i odpowiada dokładnie na zapytanie klienta. Ponieważ serwer GraphQL może pobierać dane z różnych źródeł i prezentować je w jednym wspólnym grafie, nie jest związany z konkretną bazą danych.
Przykładowe zapytanie GraphQL
Przykładowe zapytanie GraphQL może wyglądać następująco (na podstawie API naszej usługi Qtravel Search):
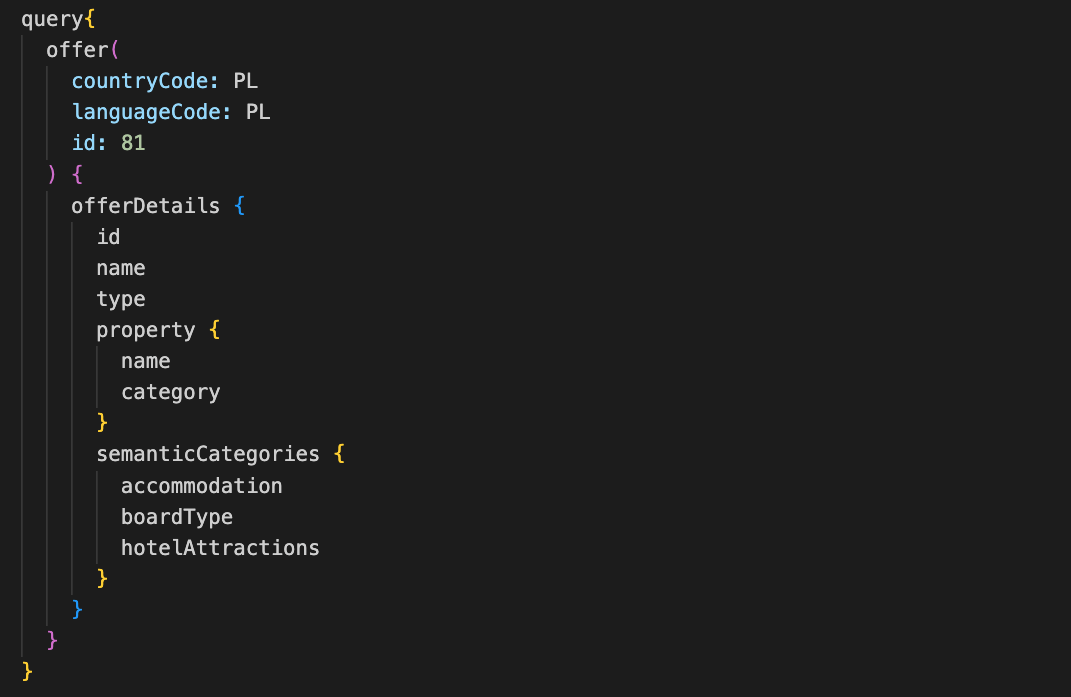
Serwer GraphQL na powyższe zapytanie zwróci odpowiedź w postaci:
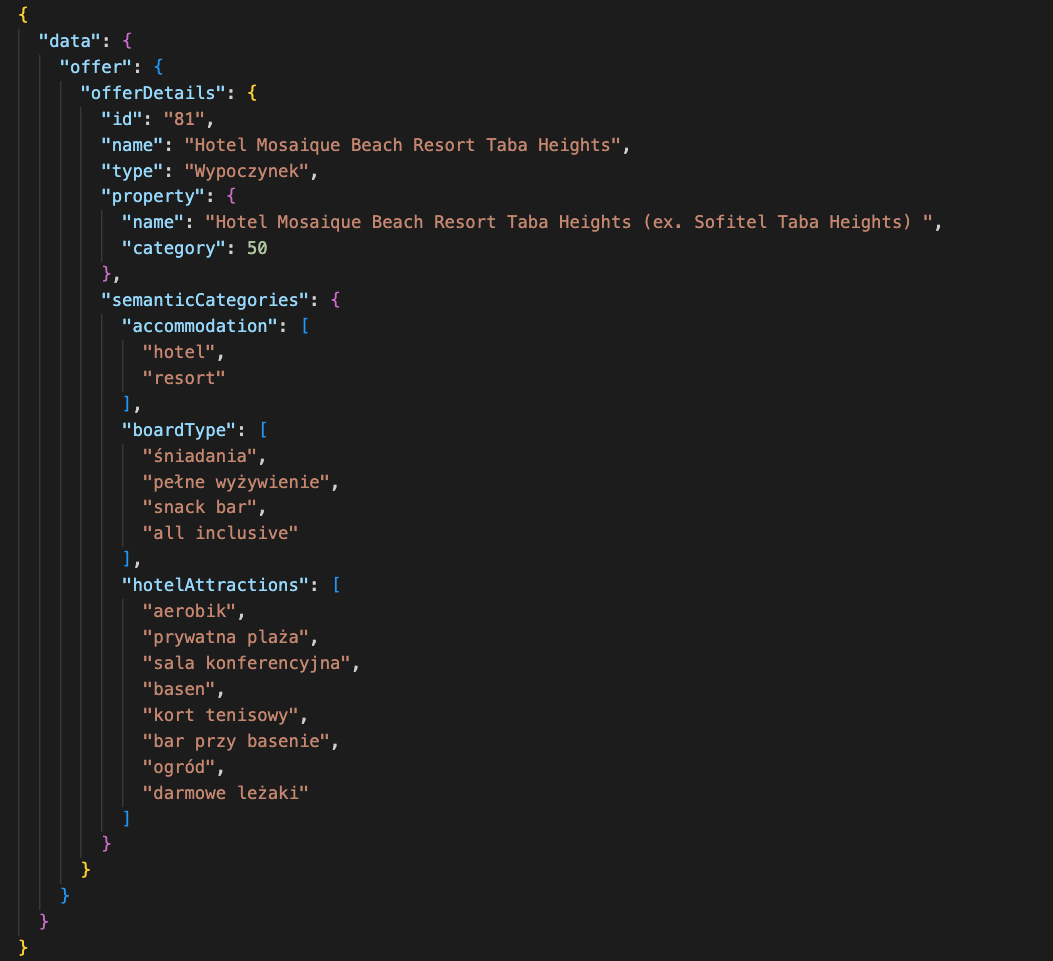
Zwrócone dane zostaną następnie wykorzystane do wyświetlenia szczegółów oferty turystycznej na stronie internetowej.
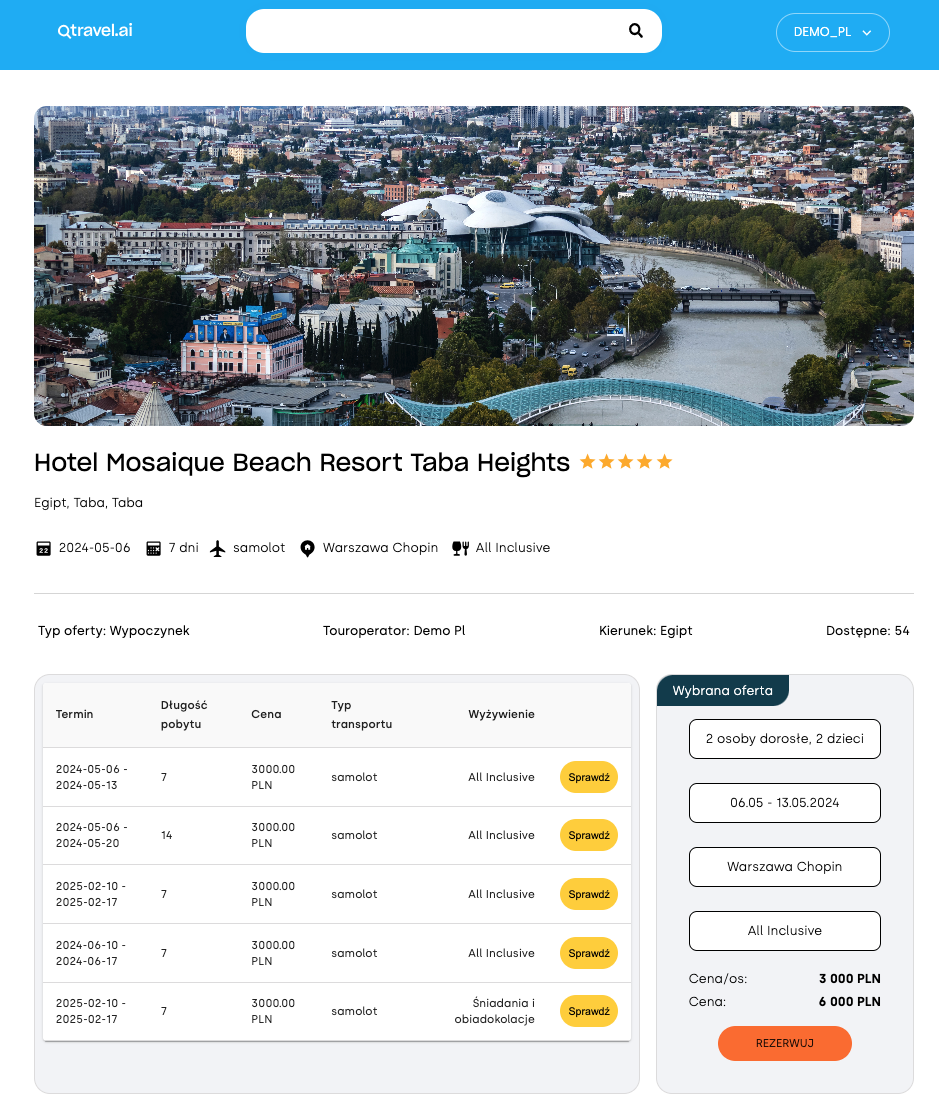
W powyższym przykładzie wykorzystaliśmy jeden z typów operacji dostępny w GraphQL- query, który służy do pobierania danych. Dwa pozostałe, które omówimy w dalszej części artykułu to:
- mutation – służy do modyfikowania danych (wykonywania operacji Create, Update, Delete)
- subscription – służy do informowania o zmianach w danych.
Dlaczego powstał GraphQL?
Zanim przejdziemy do szczegółowego omówienia GraphQL, prześledźmy pokrótce historię jego powstania, gdyż jest ona bardzo interesująca. GraphQL nie powstał w zakamarkach organizacji standaryzacyjnych, które opracowują standardy (np.: sieci komputerowych), wdrażane następnie przez producentów. GraphQL był odpowiedzią Facebooka na rosnący problem developerów firmy z interfejsami REST API, któremu przyjrzymy się bliżej w dalszej części artykułu. Prace nad GraphQL inżynierowie Facebooka rozpoczęli już w 2012 roku, ale dopiero w 2015 roku opublikowali oficjalną publiczną specyfikację GraphQL.
Problem ze standardem REST API dotyczył nie tylko Facebooka, ale wielu innych firm technologicznych działających na dużą skalę (np: Airbnb, Twitter), które korzystały z architektury REST API.
Interfejsy REST API są do tej pory niezwykle popularne. Dzięki nim możliwe jest odseparowanie warstwy backend od warstwy frontend (interfejsu graficznego) aplikacji. Komunikacja między tymi warstwami odbywa się za pomocą API, który łączy je w jedną całość. Odseparowanie warstw ma szczególne znaczenie w coraz to szybciej rozwijających się branżach e-commerce i e-travel, w których doświadczenia użytkownika oraz interfejs strony internetowej czy aplikacji mobilnej decydują o decyzjach zakupowych klientów.
REST API, pomimo popularności i łatwości implementacji, ma swoje ograniczenia, które szczególnie dotyczą warstwy frontendowej. Im więcej klientów na stronach internetowych, tym więcej „dzieje się” w warstwie frontendu i tym więcej przetwarzania danych pobieranych za pomocą API. Problem w tym, że frontend programiści najczęściej nie mają wpływu na to, jakie dane są zwracane przez interfejs API (tzw. overfetching), a często aby wyświetlić wszystkie niezbędne informacje na stronie muszą odpytać kilka interfejsów API po kolei (tzw. underfetching).
Porównanie GraphQL i REST API
Dane
Jednym z najczęstszych problemów związanych z REST API jest nadmiarowe lub niewystarczające pobieranie danych, o którym wspominaliśmy wyżej. To zjawisko występuje, ponieważ jedynym sposobem na pobranie danych jest korzystanie z tzw. endpointów, które zwracają z góry określone struktury danych. Projektowanie API w taki sposób, aby dostarczało dokładnie te dane, których akurat w tym przypadku potrzebujemy, jest bardzo trudne w rozwoju i utrzymaniu.
Overfetching – Pobieranie zbędnych danych
Nadmiarowe pobieranie danych (overfetching) oznacza – jak sama nazwa wskazuje – że pobieramy więcej informacji, niż jest nam faktycznie potrzebne.
Na przykład, jeśli w aplikacji chcemy wyświetlić listę wycieczek tylko z ich nazwami oraz cenami, to w REST API musielibyśmy odpytać endpoint /tours i otrzymać tablicę JSON z danymi wycieczek. Jednak taka odpowiedź może zawierać dodatkowe informacje o wycieczkach, takie jak zakwaterowanie, wyżywienie czy atrakcje – informacje, które są dla nas zbędne.
Underfetching – Problem n+1 zapytań
Innym problemem jest sytuacja, kiedy nasze konkretne zapytanie nie dostarcza nam wszystkich potrzebnych informacji. W tym wypadku, jesteśmy zmuszeni wysyłać dodatkowe zapytania, aby uzyskać to, czego potrzebujemy.
Jako przykładu, możemy użyć poprzedniej aplikacji, ale tym razem chcemy wyświetlać po jednym terminie dla każdej wycieczki. Dodatkowo API udostępnia nam endpoint /tours/id/terms. A więc aby wyświetlić te informacje, musimy wysłać zapytanie do /tours, a następnie dla każdej wycieczki odpytać /tours/id/terms o konkretne terminy (gdzie w tym przypadku pojawi się overfetching, ponieważ potrzebujemy jedynie pierwszego terminu). Jesteśmy więc zmuszeni wysłać zapytanie, a następnie n kolejnych zapytań – stąd nazwa samego problemu: n+1 zapytań.
A jak to robi GraphQL?
W przypadku GraphQL wystarczy wysłać pojedyncze zapytanie do serwera, w którym precyzyjnie określamy, jakie dane są potrzebne. Dzięki temu, że jest on silnie typowany, zawsze mamy gwarancję, że w otrzymanym obiekcie JSON otrzymamy oczekiwane dane. Dodatkowo dzięki zagnieżdżonej strukturze zapytania wszystkie dane ułożone są jak w wysłanym zapytaniu.
Przykładowo, dla naszego problemu możemy wysłać zapytanie:

Dzięki temu nie ma już problemu nadmiarowych lub niewystarczających danych, a my otrzymujemy dokładnie to, czego potrzebujemy.
Rozwój
Integracje z frontendem
GraphQL został zaprojektowany tak, aby doskonale współpracować z frameworkami frontendowymi, takimi jak React i Vue, co ułatwia budowanie nowoczesnych, interaktywnych aplikacji internetowych. GraphQL posiada dedykowane biblioteki i narzędzia, które umożliwiają płynną integrację.
Choć REST może być używany z frameworkami frontendowymi, integracja może wymagać więcej pracy manualnej i niestandardowych implementacji. Pomimo istnienia bibliotek innych firm, REST nie zapewnia standaryzowanego sposobu integracji z konkretnymi frameworkami frontendowymi, takimi jak React czy Vue.
Wersjonowanie
GraphQL ma przewagę, jeśli chodzi o wersjonowanie, ponieważ umożliwia oznaczanie pól, które zostaną usunięte, co daje developerom po stronie klienta czas na dostosowanie się.
W przypadku REST, to developerzy muszą zadbać o to, aby używali poprawnej wersji interfejsu API.
Praca programistyczna
GraphQL z natury bardzo dobrze się opisuje podczas tworzenia jego składni, przez co redukuje potrzebę obszernych dokumentacji i sprzyja lepszemu zrozumieniu modelu danych. Silnie typowany schemat i walidacja zapytań pozwalają na szybsze zrozumienie i jednoczesne wczesne wykrywanie błędów. Przez to, że GraphQL posiada intuicyjny język zapytań, ułatwia on wprowadzanie nowych członków zespołu i transfer wiedzy w zespole programistycznym.
Interfejsy API REST zazwyczaj polegają na nieformalnej dokumentacji lub konwencjach różniących się w różnych implementacjach. Brak wspólnego zrozumienia prowadzi do niekonsekwencji i luk w wiedzy w zespołach. To zmusza developerów, którzy są dłużej w zespole, do poświęcania cennego czasu na edukację nowych członków zespołu zamiast skupiania się na problemach biznesowych.
Schemat w GraphQL
GraphQL wspiera odczytywanie, zapisywanie (mutacje) i subskrybowanie zmian danych (aktualizacje w czasie rzeczywistym – zwykle realizowane za pomocą WebSockets).
Usługę GraphQL tworzymy poprzez definiowanie typów z polami, a następnie dostarczanie konkretnych funkcji do uzyskiwania danych dla każdego z tych pól. Typy i pola stanowią to, co nazywa się definicją schematu. Funkcje, które pobierają i mapują dane, nazywane są resolverami.
Po sprawdzeniu zgodności z schematem, zapytanie GraphQL jest wykonywane przez serwer. Serwer zwraca wynik, który odzwierciedla kształt pierwotnego zapytania, zwykle w formacie JSON.
Typy
Korzeń schematu GraphQL, domyślnie zwanego zapytaniem (Query), zawiera wszystkie pola, o które możemy zapytać. Inne typy definiują obiekty i pola, które serwer GraphQL może zwrócić. Istnieje kilka podstawowych typów, nazywanych skalarami, które reprezentują takie rzeczy jak ciągi znaków, liczby i identyfikatory.
Pola są domyślnie definiowane jako opcjonalne, a znak wykrzyknika na końcu można użyć, aby oznaczyć pole jako wymagane. Pole może być zdefiniowane jako lista, umieszczając typ pola w nawiasach kwadratowych (na przykład, trips: [Trip]).
Zapytania (Query)
Zapytanie GraphQL określa jakie dane chce uzyskać klient.
W tym przypadku interesuje nas oferta o identyfikatorze 81, z której chcemy uzyskać informacje takie jak nazwa oraz typ oferty.
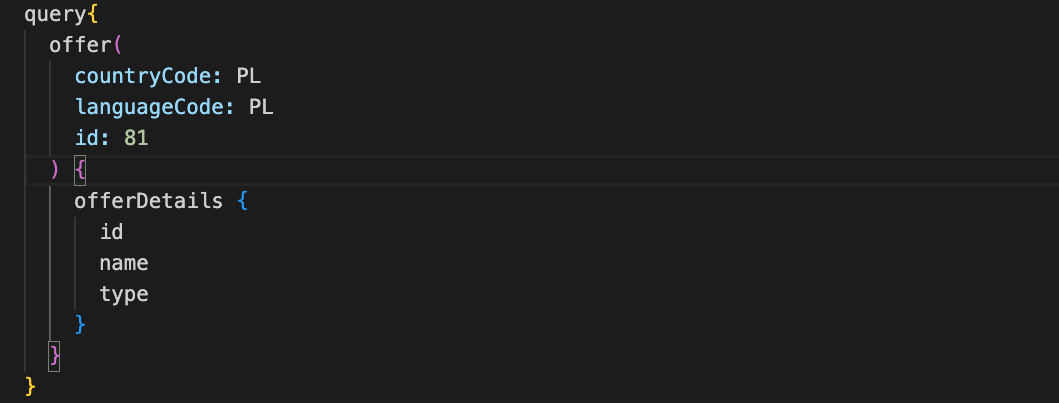
Po sprawdzeniu zgodności i wykonaniu zapytania przez serwer GraphQL, dane są zwracane w tym samym formacie jak w zapytaniu.

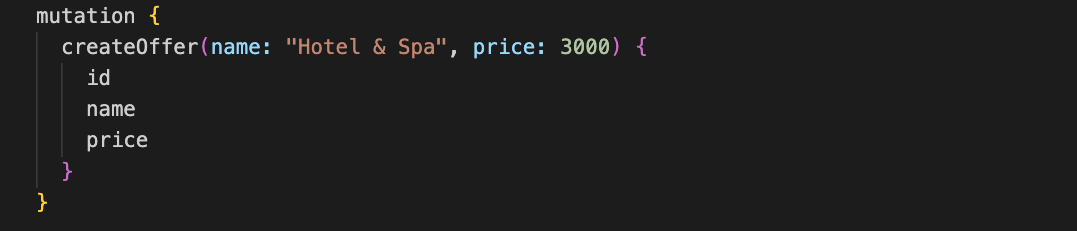
Mutacje (Mutations)
Mutacje GraphQL pozwalają na tworzenie, aktualizowanie lub usuwanie danych.
Zazwyczaj pozwalają one na przekazywanie argumentów, które umożliwiają przekazywanie danych bezpośrednio od klienta na serwer. W tym przypadku chcemy utworzyć ofertę dla hotelu Hotel & Spa za 3000 złotych.

Subskrypcje (Subscryptions)
GraphQL obsługuje również aktualizacje na żywo wysyłane z serwera do klienta w operacji nazywanej subskrypcją. Ponownie, klient definiuje dane, których potrzebuje za każdym razem, gdy zostanie dokonana aktualizacja.

W tym przypadku, klientowi zwrócone zostaną dane nowego terminu dla oferty z identyfikatorem 81, jeśli taki termin powstanie.

Serwery GraphQL
Dzięki popularności GraphQL istnieje wiele różnych implementacji serwerów, które pozwalają nam używać go niezależnie od preferowanej od nas technologii.
Istnieją takie rozwiązania jak:
- GraphQL.js dla języka JavaScript,
- graphql-go dla języka Go,
- Graphene dla języka Python,
- graphql-ruby dla języka Ruby.
Więcej rozwiązań można znaleźć na oficjalnej stronie GraphQL.
Narzędzia GraphQL
Pracę z GraphQL mogą nam ułatwić zarówno narzędzia do budowania zapytań, jak jak i przeglądania schematu naszych danych. Jednym z takich narzędzi jest GraphiQL, które można przetestować online. Podobnym narzędziem jest GraphQL Playgroud, które jest udostępnione dla serwera GraphQL firmy Apollo. Poniżej zrzut ekranu z tego narzędzia, działającego dla naszego API.
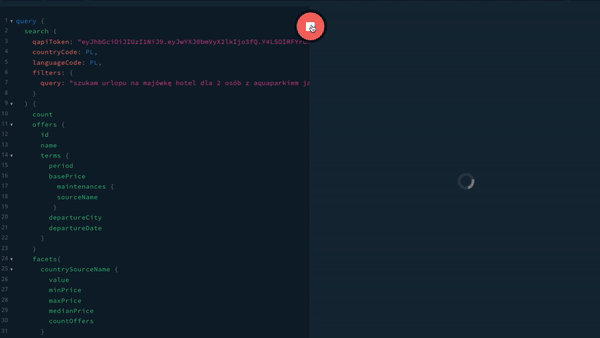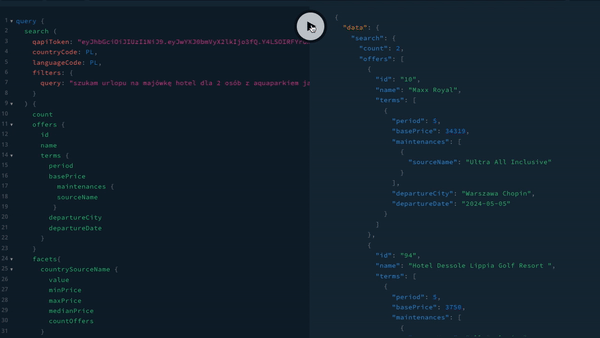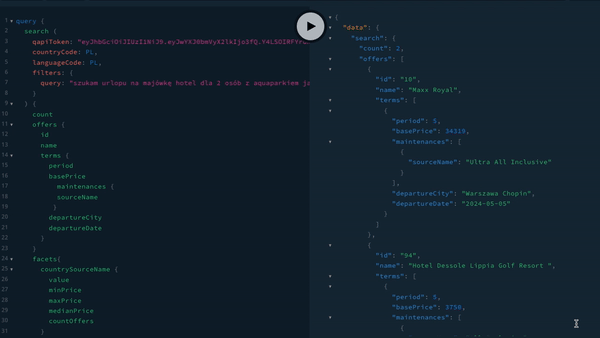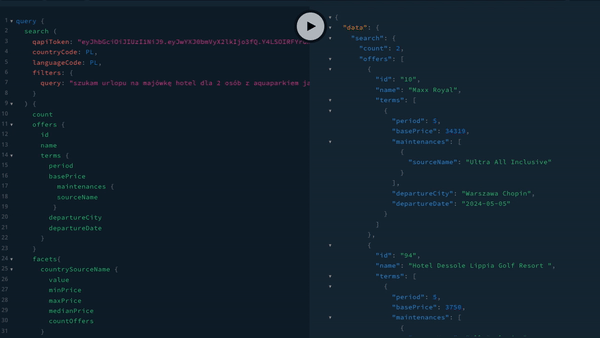
Podsumowanie
Język zapytań GraphQL wykorzystywany w Qtravel Search zapewnia bardziej elastyczne i wydajniejsze pobieranych danych, co ma szczególne znaczenie w przypadku złożonych, hierarchicznych danych ofert turystycznych.
Jeśli chcesz dowiedzieć się więcej na temat GraphQL polecamy poniższe źródła wiedzy:
- https://graphql.com/learn
- https://www.howtographql.com/
- https://www.apollographql.com/docs/
- https://graphql.org/community/tools-and-libraries/
Zachęcamy także do zabawy GraphQL i samodzielnych testów API wyszukiwarki Qtravel Search w narzędziu GraphQL Playground, które specjalnie dla Was uruchomiliśmy.