
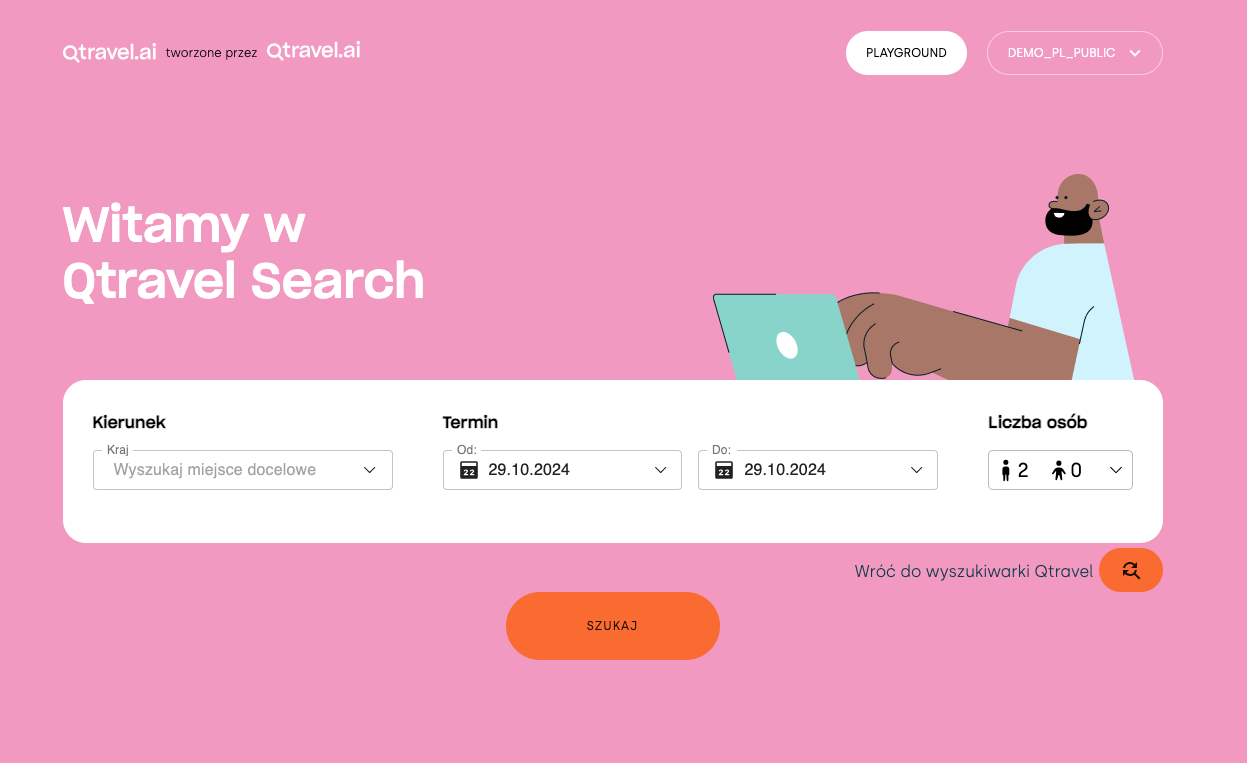
Dla każdego dostawcy usług turystycznych kluczową, a wręcz krytyczną, funkcjonalnością serwisu turystycznego jest wyszukiwarka ofert. Współczesny turysta oczekuje precyzyjnych i szybkich wyników, które spełnią jego indywidualne wymagania, takie jak budżet czy preferencje dotyczące lokalizacji, rodzaju zakwaterowania oraz aktywności. Dlatego też właściwe działanie wyszukiwarki ma fundamentalne znaczenie dla zapewnienia wysokiej jakości obsługi klienta i zadowolenia z korzystania z serwisu turystycznego.
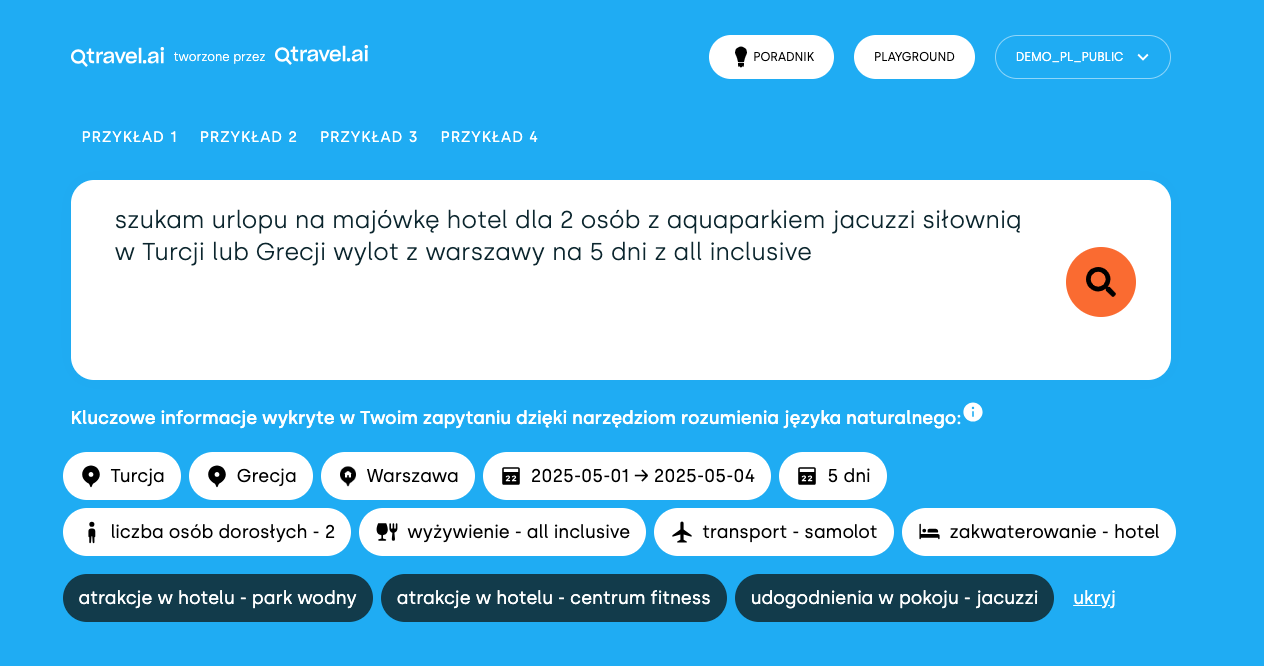
A czy zastanawialiście się, jak to możliwe, że wyszukiwarka turystyczna w ułamku sekundy znajduje idealne wakacje spośród milionów możliwych kombinacji? W tym artykule postaramy się odpowiedzieć na to pytanie, pokazując jak technologie wyszukiwania ewoluowały od prostych zapytań SQL do zaawansowanych systemów wykorzystujących Big Data. Posłużymy się realnym przykładem naszej wyszukiwarki turystycznej Qtravel Search, żeby lepiej zobrazować, jak nowoczesna architektura systemu radzi sobie z przetwarzaniem ogromnej ilości danych i zapewnieniem błyskawicznych rezultatów wyszukiwania.
Ewolucja systemów wyszukiwania
Przez wiele lat za proces wyszukiwania w aplikacjach internetowych odpowiadały zapytania formułowane w języku SQL wykonywane bezpośrednio w relacyjnej bazie danych. W wielu przypadkach takie rozwiązanie mogło być rzeczywiście wystarczające, na przykład przy mało skomplikowanej strukturze danych czy stosunkowo niewielkiej liczbie rekordów tabeli, w której realizowaliśmy wyszukiwanie. Relacyjne bazy danych najlepiej sprawdzały się w sytuacjach w których wyszukiwanie oparte było o ściśle określone kryteria – w przypadku ofert turystycznych zazwyczaj były to kategorie takie jak kraj docelowy, miejsce czy data wyjazdu.
Pseudo kod zapytania SQL o podstawowe filtry, w wyszukiwaniu klasycznym

Wraz ze wzrostem liczby danych oraz coraz bardziej złożoną strukturą, wyszukiwanie w relacyjnych bazach danych stawało się coraz bardziej skomplikowane i mniej wydajne. Rosło także zapotrzebowanie na inne funkcjonalności, których bazy RDBMS nie udostępniały. Przede wszystkim dotyczyło to wyszukiwania pełnotekstowego (ang. full-text search), które stało się domyślnym sposobem wyszukiwania w serwisach e-commerce czy tzw. “newsowych”.
Analiza preferencji użytkowników, jak i recenzje użytkowników, które odgrywają dużą rolę podczas szukania odpowiedniej oferty przez klienta, wymuszają na systemach obsługę bardziej złożonych zapytań i przetwarzanie ogromnych ilości danych w czasie rzeczywistym. Dlatego też naturalnym krokiem w rozwoju systemów wyszukiwania było wydzielenie procesu wyszukiwania do oddzielnego systemu wyszukiwania wyspecjalizowanego w wyszukiwaniu tekstowym w dużej liczbie rekordów, tzw. silników wyszukiwania (ang. search engines). Listę najbardziej popularnych silników wyszukiwania znajdziesz jest na stronie DB-Engines.
Jak działają silniki wyszukiwania?
Silniki wyszukiwania działają na zasadzie tworzenia indeksów, które umożliwiają szybkie i efektywne przeszukiwanie dużych zbiorów danych. Proces ten polega na analizowaniu dokumentów i tworzeniu struktury danych, która umożliwia szybki dostęp do informacji na podstawie zapytań. Silniki wyszukiwania wykorzystują różne techniki, takie jak tokenizacja, stemming czy filtrowanie, aby przekształcić tekst w formę optymalną do wyszukiwania. Dzięki tym procesom możliwe jest szybkie przeszukiwanie, sortowanie oraz filtrowanie danych według określonych kryteriów.
W Qtravel.ai skupiamy się na Apache Solr i ElasticSearch, opartych na bibliotece Apache Lucene, która umożliwia pełnotekstowe wyszukiwanie i analizę danych. Ich działanie można podzielić na dwa kluczowe procesy: indeksowanie danych oraz wyszukiwanie danych.
Indeksowanie danych
Indeksowanie danych to tworzenie „mapy”, która pozwala szybko znaleźć informacje. Tak jak indeks w książce ułatwia odnalezienie tematu na konkretnej stronie, tak indeks w Solr umożliwia efektywne przeszukiwanie dużych zbiorów danych. Przed rozpoczęciem indeksowania dane muszą być odpowiednio przygotowane i skonfigurowane. Solr/ElasticSearch wymagają schematu, który określa, jakie pola mają być przechowywane, jakie są ich typy (np. tekst, liczba, data) oraz jakie operacje można na nich wykonywać.
Gdy dane są już zgodne ze schematem, można rozpocząć proces tworzenia indeksu. Można to zrobić na kilka sposobów, na przykład przesyłając dane do Solr za pomocą prostych poleceń lub korzystając z narzędzi do automatyzacji. Solr przetwarza dane, analizując tekst, dzieląc go na mniejsze fragmenty (np. słowa) i tworząc indeks, który umożliwia szybkie wyszukiwanie.
Wyszukiwanie danych
Wyszukiwanie danych polega na przeszukiwaniu wcześniej utworzonego indeksu w celu znalezienia dokumentów, które najlepiej odpowiadają zapytaniu. Proces ten obejmuje analizowanie zapytania, dopasowywanie wyników na podstawie dopasowań i rankingów oraz optymalizację wyników, aby zapewnić jak najbardziej trafne rezultaty.
Proces indeksowania i wyszukiwania w Apache Solr/ElasticSearchw
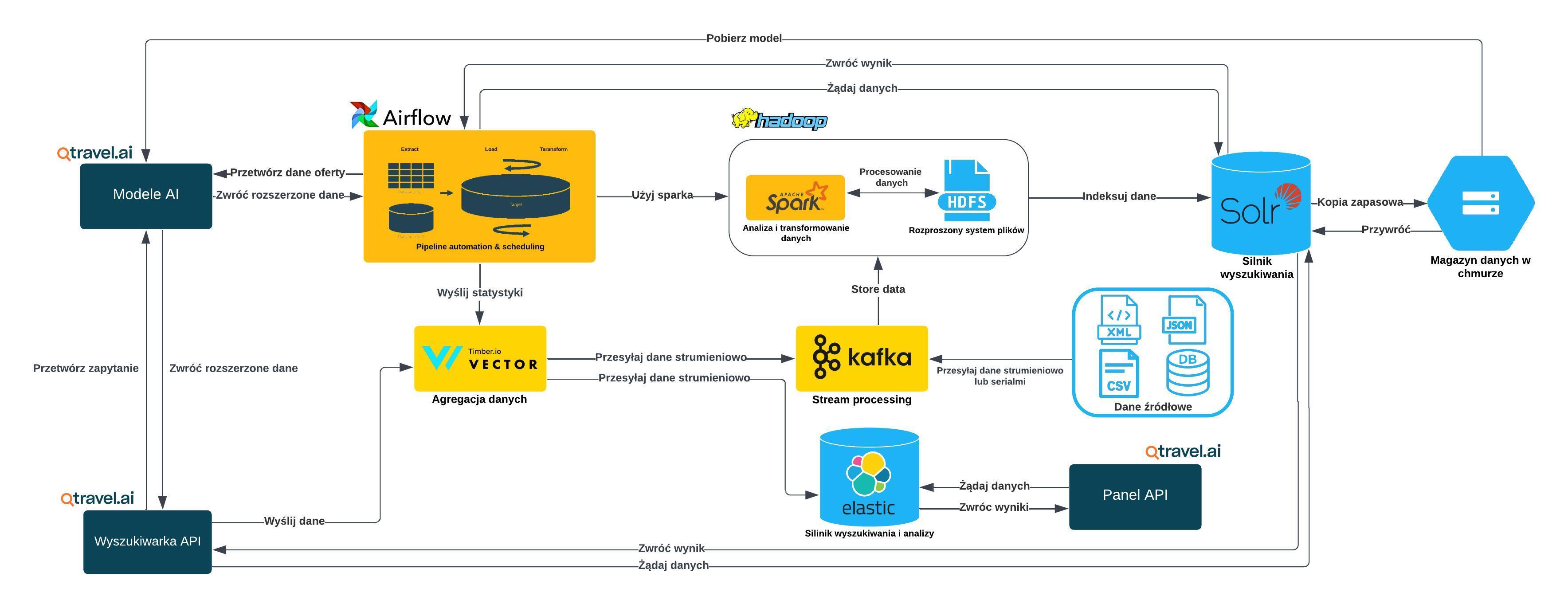
Dostarczanie danych do indeksu silnika wyszukiwania może być procesem bardzo skomplikowanym i często wymaga budowy oddzielnego systemu przetwarzania danych, który polega na pobieraniu danych z różnych źródeł i następnie przekształcaniu ich do formatu obsługiwanego przez wspomniane silniki wyszukiwania. W dalszej części artykułu, omówimy architekturę takiego systemu, który został dopasowany do przetwarzania dużych zbiorów danych turystycznych.
Dane w turystyce – jakie elementy obejmują?
Turystyka jest jedną z branż, w której dane odgrywają kluczową rolę. Każda oferta turystyczna to kompleksowy zbiór informacji, które muszą być precyzyjnie przetwarzane, zarządzane i prezentowane klientowi. W przeciwieństwie do typowego e-commerce, gdzie produkty są stosunkowo proste do opisania (np. koszulka w różnych rozmiarach i kolorach), oferta turystyczna to złożony zestaw danych, wymagający zaawansowanego zarządzania. Dane te obejmują m.in. informacje o hotelach, pokojach, lotach, wyżywieniu, konfiguracjach osób dorosłych i dzieci w pokoju oraz przede wszystkim cenach tak złożonej oferty turystycznej.
Przykładowa struktura danych w turystyce:
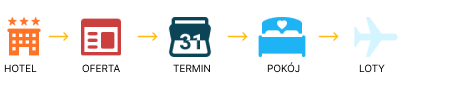
Na czym polega złożoność oferty turystycznej?
Aby zobrazować złożoność, przyjrzyjmy się jednej ofercie turystycznej do wybranego hotelu, która zawiera następujące zmienne:
- 3 typy wyżywienia: śniadania, HB, All Inclusive
- 5 lotnisk (tj. wylot możliwy z 5 różnych lokalizacji)
- Długość pobytu: możliwość wyboru między 3 a 6 dniami
- 3 typy pokojów (np. standardowy, z widokiem na morze, apartament)
- 5 różnych konfiguracji osobowych (np. 1 dorosły, 2 dorosłych, 2 dorosłych + 1 dziecko, itp.)
Obliczenie możliwych kombinacji
Dla jednej oferty liczba możliwych konfiguracji wynika z mnożenia liczby dostępnych opcji:
Liczba kombinacji = 3 (wyżywienie) × 5 (lotniska) × 2 (długość pobytu) × 3 (pokoje) × 5 (konfiguracje) = 450
Na pierwszy rzut oka nie wygląda to tak strasznie, nawet jeśli porównamy to do typowego produktu e-commerce (T-shirt), gdzie możemy uzyskać nawet 150 różnych opcji jednego produktu:
Liczba kombinacji = 10 (kolory) × 5 (rozmiary) × 3 (materiały) = 150
Jednak problem polega na tym, że w turystyce, oprócz różnorodnych konfiguracji oferty, należy również uwzględnić daty i okresy dostępności, co znacznie zwiększa liczbę możliwych kombinacji.
Załóżmy, że mamy 450 możliwych kombinacji dotyczących wyżywienia, lotnisk, czasu trwania, pokoi i innych konfiguracji oferty.
Musimy również uwzględnić częstotliwość wylotów:
Liczba kombinacji na rok = 450 (liczba kombinacji) × 365/3 (wyloty co 3 dni) = 54 750
Jeśli teraz pomnożymy liczbę wszystkich kombinacji przez liczbę ofert:
Liczba wszystkich kombinacji = 54 750 (liczba kombinacji na rok) × 1000 (liczba ofert) = 54 750 000
Co więcej, biura podróży często chcą pokazać oferty na kolejne sezony, co może zwiększyć okres, na jaki są tworzone kombinacje, z jednego roku do np. dwóch lat.
Na podstawie powyższych informacji widać, że oferta turystyczna jest o wiele bardziej złożona niż typowy produkt e-commerce. Tak duża liczba zmiennych i możliwych kombinacji sprawia, że dostosowanie oferty do potrzeb klienta wymaga zaawansowanych systemów zarządzania danymi oraz efektywnego ich przetwarzania.
Architektura przetwarzania danych turystycznych
W turystyce mamy do czynienia z ogromną ilością danych – wyobraźmy sobie miliony kombinacji ofert turystycznych, które zmieniają się na bieżąco. Dodatkowo, klienci poszukują ofert turystycznych, które spełniają ich szczegółowe kryteria, na przykład dotyczące daty wyjazdu czy zaplanowanego budżetu. To wymaga szybkiego, efektywnego przetwarzania i analizowania informacji, co w tradycyjnych systemach wyszukiwania opartych na relacyjnych bazach danych jest bardzo trudne.
Ze względu na dynamicznie zmieniające się ceny oraz dostępność terminów w turystyce, zamiast tradycyjnych rozwiązań, w Qtravel Search wdrożyliśmy system oparty na technologiach typowych dla przetwarzania dużych zbiorów danych (Big Data), takich jak:
- Apache Hadoop – system, który pozwala nam przechowywać duże ilości danych, rozkładając je na różne serwery. Dzięki temu nawet olbrzymie zbiory danych mogą być szybko analizowane.
- Apache Spark – narzędzie, które umożliwia szybkie przetwarzanie tych danych. W przeciwieństwie do tradycyjnych systemów, Spark przetwarza dane w pamięci, co znacznie przyspiesza analizy.
- Apache Airflow – narzędzie, które zarządza i automatyzuje nasze zadania związane z przetwarzaniem danych. Dzięki niemu, procesy przetwarzania danych turystycznych są zorganizowane, a wyniki dostarczane na czas.
Koncepcje Przetwarzania
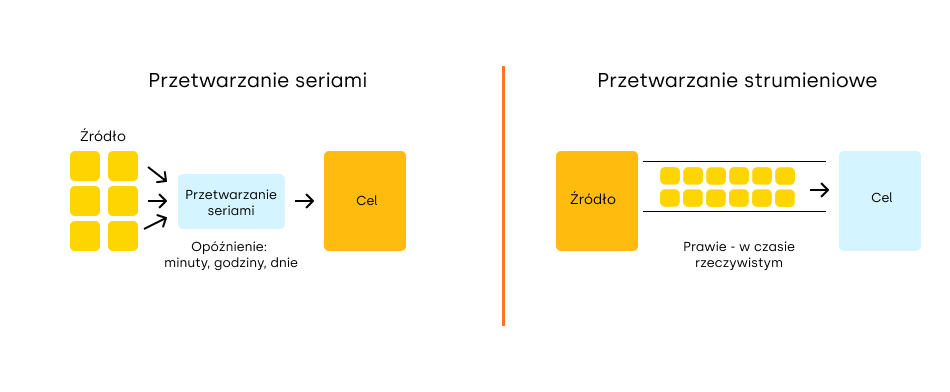
Przetwarzanie seriami
Przetwarzanie seriami (ang. batch processing) polega na analizowaniu dużych zbiorów danych zgromadzonych w dłuższych okresach czasu. Dane są zbierane, a następnie przetwarzane w partiach, co jest efektywne w przypadku, gdy nie ma potrzeby natychmiastowej analizy. To podejście jest szeroko stosowane w procesach, które wymagają dużej mocy obliczeniowej, takich jak generowanie raportów, analizy historyczne czy obliczenia statystyczne. Apache Spark jest świetnie przystosowany do przetwarzania batchowego dzięki swojej zdolności do równoległego przetwarzania danych w klastrze, co przyspiesza analizę dużych ilości informacji.
Przetwarzanie strumieniowe
Przetwarzanie strumieniowe (ang. streaming processing) skupia się na analizie danych w miarę ich napływania, co pozwala na natychmiastową reakcję na zmieniające się warunki, takie jak zmiany w dostępności ofert, biletów, cen czy innych dynamicznych informacji (np. godzin wylotów). Jest idealne w sytuacjach, w których kluczowy jest dostęp do informacji w czasie rzeczywistym (real-time processing) lub zbliżonym do rzeczywistego (near real-time processing), takich jak monitorowanie zdarzeń, dynamiczne ustalanie cen czy zarządzanie transakcjami finansowymi. Apache Spark Streaming umożliwia przetwarzanie danych strumieniowych, dostarczając wyniki niemal natychmiast po ich pojawieniu.
Podsumowanie
Wybór odpowiedniej architektury przetwarzania danych turystycznych jest kluczowy dla zapewnienia wydajności i skalowalności. Apache Hadoop i Apache Spark, dzięki swoim możliwościom, stanowią bardzo dobre rozwiązanie do obsługi zarówno przetwarzania batchowego, jak i strumieniowego, spełniając potrzeby współczesnych aplikacji turystycznych.
Jeśli chcesz dowiedzieć na ten temat, polecamy zapoznać się z poniższymi źródłami wiedzy:
- Apache Spark™ – Unified Engine for large-scale data analytics
- Apache Hadoop
- Apache Airflow
- Apache Solr Reference Guide :: Apache Solr Reference Guide
- Batch vs Stream Processing: When to Use Each and Why It Matters
A jeśli chcesz przetestować naszą wyszukiwarkę, aby dowiedzieć się, jak działa w praktyce – koniecznie sprawdź demo tego rozwiązania.