
W dzisiejszym świecie właściwie dopasowane rekomendacje stały się kluczowym elementem pozytywnych doświadczeń użytkownika. Dzięki nim możemy sprawnie podpowiedzieć klientom, jakie treści mogą ich jeszcze zainteresować, a tym samym — zachęcić do sprawdzenia szerszego wachlarza naszej oferty. Systemy rekomendacji wykorzystujące analizę podobieństwa tekstu efektywnie łączą użytkowników z najbardziej odpowiednimi dokumentami, oszczędzając ich czas i wysiłek.
W niniejszym artykule omówimy, jak działają systemy rekomendacji oparte na podobieństwie treści. Skupimy się na dwóch fundamentalnych algorytmach – TF-IDF oraz BM25.
Omówimy, jak działają, czym się od siebie różnią, a także pokażemy, jak za pomocą narzędzia Qtravel Search API możemy w szybki sposób uruchomić rekomendacje ofert turystycznych opartych na ww. algorytmach.
Czym są algorytmy rekomendujące treści?
Zanim przejdziemy do szczegółowego omówienia metod TF-IDF oraz BM25, wyjaśnijmy, czym właściwie jest rekomendowanie ofert na podstawie podobieństwa treści.
Spójrzmy na przykład ze strony empik.com:
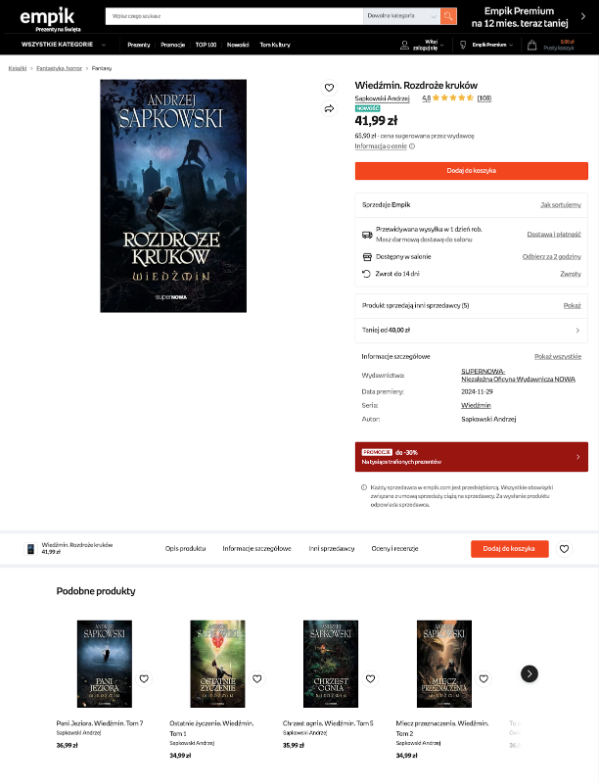
Kiedy przeglądamy informacje książce „Wiedźmin: Rozdroże Kruków”, pod głównym opisem produktu system rekomenduje nam sekcję „Podobne produkty”. Znajdują się tam inne części sagi o Wiedźminie, powieści Sapkowskiego oraz podobne książki fantasy. To właśnie przykład działania rekomendacji opartych o podobieństwo treści – system analizuje opis książki, jej kategorie, tagi oraz inne metadane, by wskazać produkty najbardziej zbliżone tematycznie.
Rekomendowanie ofert na podstawie podobieństwa treści (ang. text-similarity lub content similarity) to jeden z podstawowych mechanizmów stosowanych w silnikach wyszukiwania pełnotekstowego. System analizuje teksty opisujące produkty i na tej podstawie określa, które z nich są do siebie najbardziej podobne.
Do realizacji tego zadania wykorzystuje się zaawansowane algorytmy, takie jak TF-IDF (ang. Term Frequency-Inverse Document Frequency) oraz BM25 (ang. Best Matching 25). Oba podejścia pozwalają na ocenę ważności słów w dokumentach i ich dopasowania do zapytań, stanowiąc podstawę wielu nowoczesnych systemów wyszukiwania i rekomendacji, takich jak Apache Solr, Elasticsearch, OpenSearch i innych wyszukiwarek opartych na bibliotece Lucene.
Metryki podobieństwa treści
Głównym elementem pozwalającym na tworzenie rekomendacji opartych na treści są metryki podobieństwa. Jak sama nazwa wskazuje, służą one do wyrażenia podobieństwa pomiędzy dowolnymi tekstami w postaci skalarnej. Wynik ten (ang. score) posłuży nam do sortowania danych dokumentów tak, aby te z największymi wartościami proponowane były klientowi jako pierwsze. Innymi słowy, im większa wartość podobieństwa, tym dokument jest bardziej podobny do zapytania. Aby móc dokładniej zinterpretować otrzymywane wyniki, sprawdźmy, w jaki sposób obliczyć te wartości.
TF-IDF
Term Frequency-Inverse Document Frequency (TF-IDF) to jeden z najlepszych i jednocześnie najprostszych sposobów obliczania podobieństwa w korpusie dokumentów tekstowych. Wyraża się go jako iloczyn dwóch składowych TF oraz IDF:
Term Frequency (TF), czyli częstość terminu, którą określa się poprzez liczbę wystąpień badanego terminu w dokumencie podzieloną przez ogólną liczbę terminów w dokumencie.

Fakt, iż korzystamy ze stosunku tych dwóch liczb, a nie samej liczby wystąpień danego terminu nie jest przypadkowy. Weźmy pod uwagę taki przykład:
Badany termin: Portugalia.
Dokument A
> Tydzień pobytu w Sewilli. Zwiedzanie zabytków starego miasta i okolic z jednodniową wycieczką do Portugalii. W Portugalii zobaczymy ocean oraz nieziemską plażę
22 słowa, “Portugalia” pojawia się 2 razy.
Dokument B
> Wycieczka objazdowa po Portugalii z lokalnym przewodnikiem.
7 słów, “Portugalia” pojawia się tylko raz.
Gdybyśmy uwzględniali tylko liczbę wystąpień badanego terminu , to moglibyśmy wywnioskować, że dokument A jest dwa razy “mocniej” związany z terminem Portugalia niż dokument B, co jest oczywiście nieprawdą, bo widzimy, że to dokument B przedstawia wycieczkę po Portugalii, a w dokumencie A jest tylko wzmianka o jednodniowym wypadzie. Po normalizacji zaś, otrzymamy wartości TF równe odpowiednio 1/11 dla dokumentu A oraz 1/7 dla dokumentu B, na podstawie czego wnioskujemy, że to właśnie ten drugi jest bardziej związany z terminem Portugalia.
Inverse Document Frequency (IDF), czyli odwrotna częstość w dokumentach, to logarytm ze stosunku liczby dokumentów w indeksie do liczby dokumentów zawierających co najmniej jedno wystąpienie badanego terminu.
Stosunek, który jest liczbą logarytmowaną to w zasadzie odwrotność wartości DF, która oznacza częstość występowania dokumentów z badanym terminem. Analogicznie do poprzedniej składowej, dokonujemy normalizacji dzieląc tę liczbę przez ogólny rozmiar korpusu.
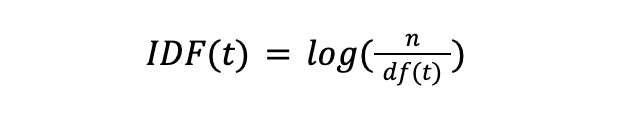
gdzie:
-
- n – liczba dokumentów w indeksie
- df(t) – liczba dokumentów zawierających termin t
Po wyjaśnieniu składowych możemy wywnioskować, że: metryka TF-IDF wskazuje nam, na ile dany termin jest ważny w danym korpusie dokumentów.
BM25
Best Matching 25 jest ulepszoną wersją metody TF-IDF, stworzoną do bardziej precyzyjnego wyszukiwania informacji oraz wyznaczania podobieństwa dokumentów do zapytań. Obydwie metody polegają na uwzględnieniu: TF – częstotliwości danego terminu w dokumencie oraz IDF – unikalności terminu w całym korpusie. Obydwa rozwiązania nadają większą wagę terminom, które często występują w konkretnych dokumentach, a rzadziej w całym indeksie dokumentów. Gdzie więc ulepszenie starszej z metod?
Kluczowe różnice pomiędzy algorytmami BM25 a TF-IDF:
1.Term Frequency (TF) a nasycenie w BM25: W BM25 stosujemy tzw. mechanizm nasycenia częstotliwości. Oznacza to, że każde kolejne wystąpienie terminu zwiększa wagę coraz mniej znacząco. Dzięki temu termin pojawiający się 100 razy nie jest uznawany za 10 razy bardziej istotny niż termin występujący 10 razy. Zapobiega to dominacji często powtarzających się terminów w bardzo długich dokumentach.
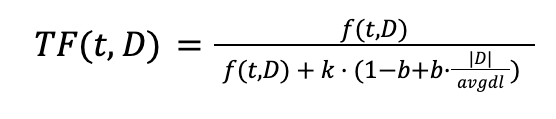 gdzie k, reguluje wpływ nasycenia.
gdzie k, reguluje wpływ nasycenia.
2.Długość dokumentu: W obydwu metodach długość dokumentu obniża końcowy wynik. BM25 natomiast wprowadza dynamiczną korektę długości dokumentu za pomocą parametru b. Dokumentom znacznie dłuższym od średniej długości dokumentów w kolekcji przypisuje niższe wyniki, ale w sposób kontrolowany:

gdzie b0,1. Dla b=0 długość nie ma znaczenia, a dla b=1 wpływ długości jest maksymalny.
3.Inverse Document Frequency: IDF w metodzie BM25 jest bardziej zaawansowany. Stosuje się “wygładzanie” (ang. smoothing) przez dodanie stałych, aby uniknąć problemów z rzadkimi terminami występującymi w bardzo małej liczbie dokumentów lub żadnym.
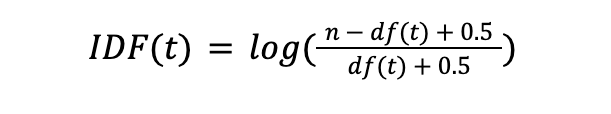
Zastosowanie w systemach rekomendacji
Wiedząc już jak działają omówione algorytmy, przejdźmy do praktycznego przypadku użycia. Qtravel Search API umożliwia wyszukanie i rekomendację podobnych ofert turystycznych na podstawie analizy ich opisów oraz metadanych. Wykorzystując silnik wyszukujący oraz metrykę podobieństwa BM25, możemy polecić klientowi wiele wycieczek o zbliżonych cechach.
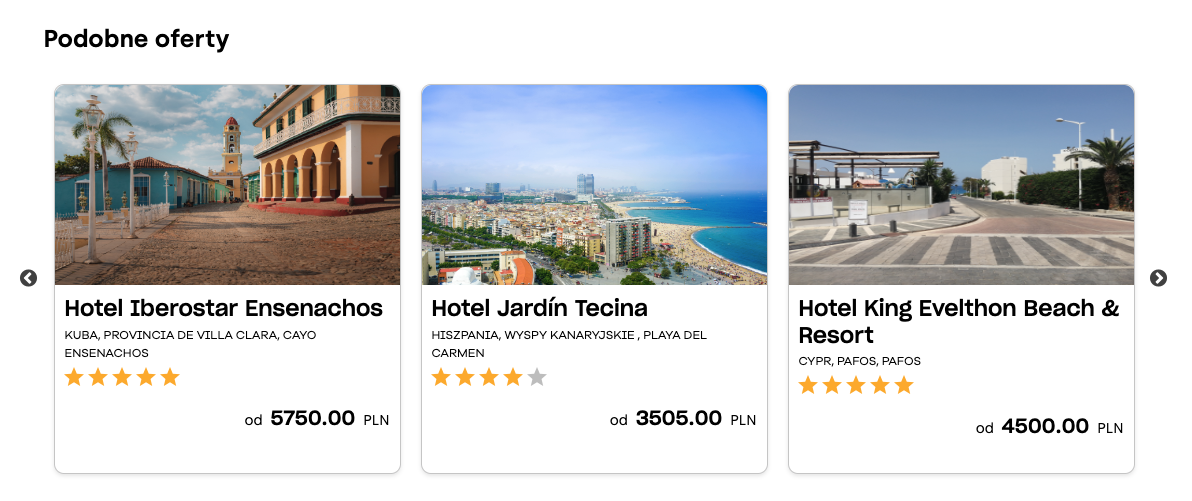
Na przykład, dla zapytania tygodniowy wyjazd do Hiszpanii otrzymaliśmy ciekawą ofertę pobytu w hotelu na Wyspach Kanaryjskich (Grafika 1.), a dla tej oferty wachlarz możliwości o podobnym charakterze (Grafika 2.).

Rekomendacja ofert za pomocą Qtravel Search API
W Qtravel Search API zaimplementowaliśmy mechanizm rekomendacji ofert turystycznych, który już teraz możesz wypróbować w naszym GraphQL Playground.
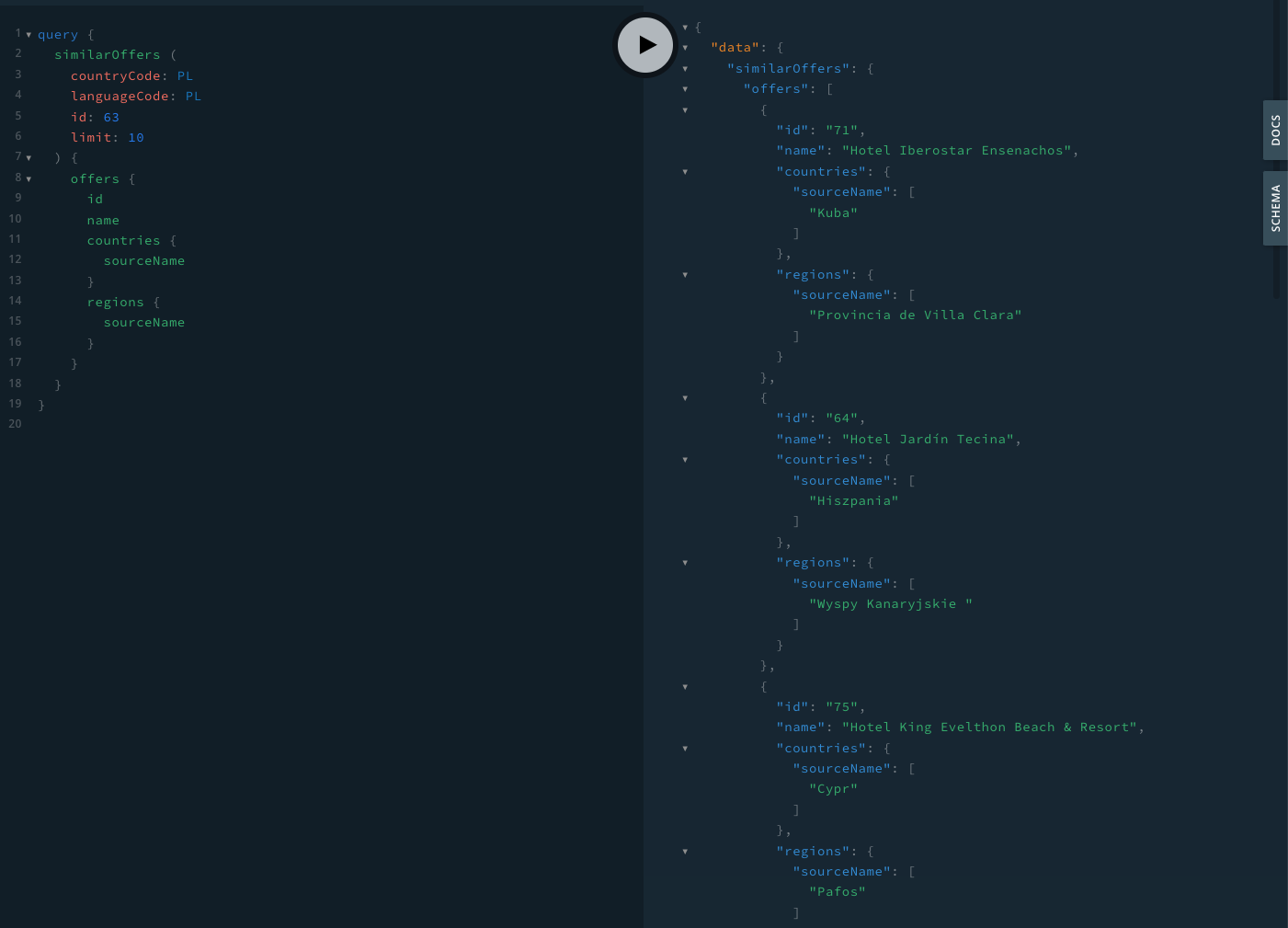
Dzięki tej aplikacji, możesz podejrzeć dokumentację oraz schemat zapytania i odpowiedzi. W tym przypadku interesuje nas zapytanie similarOffers.
Jeśli struktura zapytania GraphQL nie jest Ci jeszcze znajoma – zachęcamy do przeczytania naszego wpisu na temat Co to jest GraphQL i dlaczego warto go używać?.
Jak widać na poniższym przykładzie, jako argument zapytania similarOffers musimy podać unikatowy identyfikator oferty jako parametr id. Identyfikator ten wskazuje na ofertę której dane posłużą nam do obliczeń wartości BM25. Posługując się wcześniejszym przykładem hotelu na Wyspach Kanaryjskich, użyjemy tu id równego 63. Oprócz tego, możemy wybrać dane ofert, które chcemy wyświetlić, np. identyfikator, nazwa oferty, kraj, region oraz obszerny opis oferty, na podstawie którego w głównej mierze dokonujemy porównania.

Po wysłaniu takiego zapytania, Qtravel Search API zwróci nam listę dziesięciu najbardziej podobnych ofert, wyznaczonych za pomocą metody BM25. Oto kilka z nich:

Wypróbuj systemy rekomendacji treści w praktyce
Mamy nadzieję, że nasz artykuł przybliżył Ci temat systemów rekomendacji opartych na podobieństwie tekstu. Rozwiązania te już dawno zrewolucjonizowały branżę e-commerce, a teraz z powodzeniem możemy wykorzystać je także w branży turystycznej. Dzięki nim nie tylko usprawnimy naszym użytkownikom wyszukiwanie, ale przede wszystkim zaoszczędzimy ich czas, zwiększając satysfakcję z korzystania z naszych serwisów.
Chcesz zobaczyć inteligentne rekomendacje w praktyce? Otwórz GraphQL Playground, użyj zapytania similarOffers i przekonaj się, jak błyskawicznie system znajduje powiązane oferty. To prostsze niż myślisz – wystarczy jedno kliknięcie, by zobaczyć, jak skutecznie działa dopasowywanie podobnych treści.