Zastanawiasz się, jak technologie uczenia maszynowego są wykorzystywane do dostarczania spersonalizowanych i dokładnych wyników wyszukiwania? Poznaj tajniki „Learning to Rank” – klucza do lepszej personalizacji w świecie turystyki i nie tylko. W tym artykule wyjaśnimy, co kryje się za tym pojęciem, jak działa oraz czym różni się od systemów rekomendacyjnych. Omówimy też różne rodzaje algorytmów uczenia się rankingu oraz podamy przykładowe zastosowanie – oczywiście z branży turystycznej.
Czym jest Learning to Rank?
Metody „Learning to Rank” (LTR) to rodzaj uczenia maszynowego, który specjalizuje się w opracowywaniu technik i algorytmów do sortowania i rankingu zbiorów danych w odpowiedniej kolejności. Zazwyczaj jest stosowany w aplikacjach związanych z przetwarzaniem języka naturalnego (NLP), wyszukiwaniem informacji i rekomendacjami.
Learning to Rank w turystyce
W dziedzinie podróży LTR może być wdrożony w celu oferowania spersonalizowanych rekomendacji dla użytkowników, analizując zapytania wyszukiwania. Na przykład, gdy użytkownik wyszukuje loty z Nowego Jorku do Londynu, LTR może rankować wyniki w kolejności istotności na podstawie kilku czynników, takich jak czas lotu, cena i godzina odlotu. Zapewnia to, że użytkownik otrzymuje najbardziej odpowiednie wyniki i oszczędza czas, nie musząc przeglądać nieistotnych opcji.
Learning to Rank w e-commerce
W e-commerce LTR może być wdrożony w celu dostarczania spersonalizowanych rekomendacji produktów dla klientów, analizując ich preferencje zakupowe. Na przykład, gdy klient przegląda sklep internetowy w poszukiwaniu ubrań, model może dostarczyć rekomendacje uwzględniając różne czynniki, takie jak marka, rozmiar, sezon, kolor.
Ważnym czynnikiem jest CTR (Click-Through Rate), który odnosi się do stosunku liczby kliknięć do liczby wyświetleń produktu. Na przykład, jeśli produkt ma wysoki CTR, oznacza to, że jest on atrakcyjny dla klientów i prawdopodobnie spełnia ich oczekiwania. W takim przypadku, model może priorytetyzować rekomendacje podobnych produktów, które uzyskują wysokie CTR. Optymalizacja modelu z uwzględnieniem CTR pozwala zwiększyć szanse kliknięcia produktu i docelowo zwiększyć sprzedaż dla sklepu internetowego. Rozwiązanie LTR stosowane jest w serwisie e-commerce Amazon.
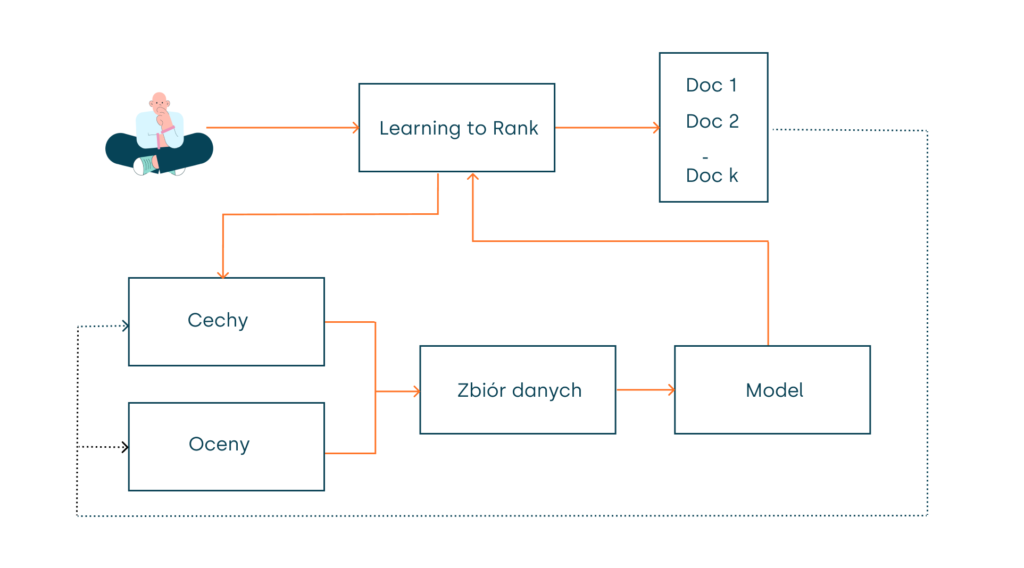
Jak działa proces re-rankingu?
Głównym celem re-rankingu jest nauczenie modelu, jak ułożyć zestaw dokumentów w sposób zgodny z intencjami użytkownika. Gdy użytkownik korzysta z wyszukiwarki, pobierane są odpowiednie dokumenty z katalogu, następnie algorytm układa je w kolejności według dopasowania do zapytania.
Przykładowe zastosowanie re-rankingu w branży turystycznej
Aby zilustrować, jak działa proces re-rankingu, rozważmy następujący scenariusz:
Wyobraź sobie system wyszukiwania specjalizujący się w oferowaniu użytkownikom sugestii dotyczących podróży. Jego głównym celem jest prezentowanie propozycji tras podróży zgodnych z preferencjami i zainteresowaniami użytkowników. Jednak równie ważne jest zrównoważenie rekomendacji ofert popularnych i rekomendacji unikalnych celów podróży.
Początkowo rankinguje opcje podróży na podstawie ich popularności. Ranking ten może uwzględniać metryki, takie jak liczba podróżujących, którzy zwiedzili te trasy lub opinie użytkowników. W rezultacie najczęściej odwiedzane miejsca znajdują się na szczycie wyników wyszukiwania. Jednak niektórzy użytkownicy mogą woleć odkrywanie mniej znanych lub niszowych celów podróżniczych.
Aby temu sprostać, system integruje algorytm rekomendacji, który uwzględnia preferencje osobiste użytkownika, interpretując jego zapytania wyszukiwania. Gdy użytkownik rozpoczyna wyszukiwanie tras podróży, model rekomendacji bierze pod uwagę zarówno początkowy ranking popularności, jak i spersonalizowane rekomendacje. Może zacząć od prezentacji popularnych tras podróży na początku wyników wyszukiwania. Następnie, może doskonalić wyniki wyszukiwania i rekomendacje, uwzględniając konkretne zapytanie użytkownika.
W ten sposób model łączy cechy popularności i personalizacji. Użytkownicy otrzymują rekomendacje popularnych miejsc podróży, jednocześnie dostosowane do ich preferencji, unikając skrajności polegającej na oferowaniu tylko popularnych opcji podróży.
Rodzaje algorytmów uczenia się rankingu
Algorytmy uczenia rankingu (LTR) należą do kategorii uczenia nadzorowanego, co oznacza, że wymagają danych wejściowych i wyjściowych. W kontekście LTR, dane wejściowe zazwyczaj stanowi identyfikator użytkownika, natomiast dane wyjściowe to lista uporządkowana według istotności dla zapytania użytkownika.
Niektóre z najczęściej używanych algorytmów LTR wykorzystują głębokie sieci neuronowe zaprojektowane do nauki i rozpoznawania złożonych wzorców w danych. Inne algorytmy LTR wykorzystują wzmacnianie (boosting), łącząc wiele słabszych modeli w celu stworzenia silniejszego modelu, lub drzewa decyzyjne, które służą do klasyfikowania danych na podstawie serii decyzji binarnych. Dzięki wykorzystaniu tych zaawansowanych algorytmów, model skutecznie uczyć się rankować dane na podstawie wielu czynników i poprawiać swoją dokładność w czasie.
Istnieją trzy główne typy algorytmów LTR: punktowe, parami oraz listowe. Wybór metody zależy od konkretnego zadania. W kolejnej sekcji omówimy każdy typ bardziej szczegółowo.
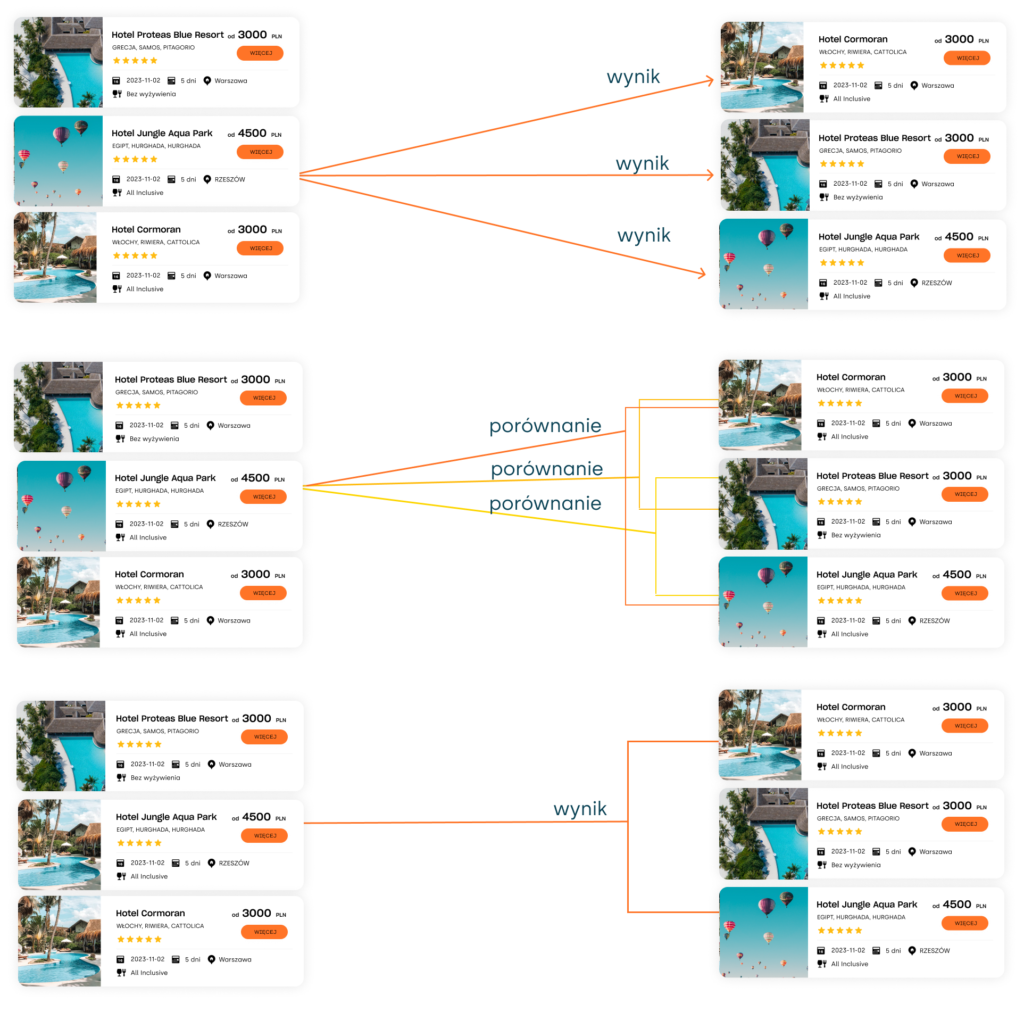
1. Metody punktowe
Metody punktowe przypisują ocenę każdemu elementowi i układają je zgodnie z tą oceną. Przekształcają problem rankingu w zadanie regresji lub klasyfikacji. Każdy punkt danych jest traktowany niezależnie, a celem algorytmu jest przewidywanie istotności konkretnego elementu w kontekście rankingu. Metody punktowe są proste i łatwe do wdrożenia, ale nie uwzględniają relacji między elementami.
2. Metody parami
Metody parami to klasyfikatory binarne, które biorą dwa elementy i zwracają ich porządek. Wynik jest zoptymalizowany w taki sposób, aby liczba inwersji między elementami była minimalna w porównaniu do optymalnego rankingu elementów. Inwersja oznacza, że dwa elementy zamieniają się miejscami. Aby przeprowadzić rankingowanie parami, potrzebujesz absolutnego porządku. Absolutny porządek oznacza, że dla dowolnych dwóch elementów katalogu możesz powiedzieć, który jest bardziej istotny niż drugi lub czy są sobie równe. Porównują pary elementów w zestawie danych i uczą się, który z nich jest bardziej odpowiedni. Metody parami są bardziej złożone niż metody punktowe, ale uwzględniają relacje między elementami.
3. Metody listowe
Metody listowe stanowią najbardziej wszechstronną podgrupę algorytmów LTR, ponieważ optymalizują całą uporządkowaną listę. Metody listowe traktują cały zbiór dokumentów jako jedną listę i starają się optymalizować ranking całej listy. Metody listowe są bardziej złożone niż metody punktowe i parami, ale uwzględniają relacje między wszystkimi elementami na liście.
Porównanie systemów rekomendacyjnych i LTR
Modele rekomendacji są projektowane do przewidywania preferencji i ocen użytkowników dotyczących konkretnych przedmiotów. Ich celem tych jest oszacowanie, czy użytkownik polubi określony przedmiot i przypisanie mu oceny lub punktacji. Na przykład model rekomendacji podróży może przewidzieć, że użytkownik oceni podróże na 4 z 5 gwiazdek i może rekomendować oferty podróży zgodnie z tą prognozą.
Natomiast algorytmy LTR nie przewidują ocen, ale skupiają się na określeniu optymalnego porządku lub rankingu listy ofert. Zajmują się tworzeniem uporządkowanych list przedmiotów na podstawie ich istotności, co czyni je bardziej odpowiednimi do scenariuszy, w których kolejność prezentacji ma znaczenie, takich jak wyszukiwarki. W wyszukiwarce algorytm LTR określa kolejność wyników wyszukiwania, przy czym najbardziej istotne wyniki pojawiają się na górze. Jest on również używany w scenariuszach rekomendacji treści, w których kolejność polecanych przedmiotów ma znaczenie.
Na czym polega różnica między przewidywaniem ocen a rankingowaniem?
W uczeniu maszynowym, uczenie się rankingu (LTR) odgrywa znaczącą rolę w wyszukiwarkach internetowych. LTR to zbiór algorytmów, które służą do szkolenia modeli rekomendacyjnych i innych aplikacji opartych na danych, aby generować uporządkowane listy.
W przeciwieństwie do rekomendacji opartych na ocenach przedmiotów, LTR nie skupia się na dokładnym przewidywaniu ocen, ale zamiast tego koncentruje się na tworzeniu list przedmiotów odpowiednio uporządkowanych. Głównym celem LTR jest dostarczenie najbardziej odpowiednich wyników dla konkretnego zapytania użytkownika.
Różnica między przewidywaniem ocen a rankingowaniem polega na tym, że ranking podkreśla pozycję przedmiotu na liście, a nie jego faktyczną ocenę. Innymi słowy, nie ma znaczenia, czy przedmiot ma wysoki wynik lub mieści się w skali ocen, o ile wynik ten reprezentuje pozycję w rankingu.
Podsumowanie
Podsumowując, technika LTR jest jak trener uczący drużynę, jak wygrywać mecze. Podobnie jak trener uczy drużynę współpracy, LTR szkoli model do tworzenia uporządkowanych list. Zarówno trener, jak i uczenie rankingu koncentrują się na budowaniu zespołu lub listy, która jest właściwie uporządkowana, zamiast skupiać się wyłącznie na ocenach lub wynikach indywidualnych.
Jeśli chcesz poznać więcej technicznych pojęć z dziedziny sztucznej inteligencji – koniecznie dołącz do naszego newslettera. Zapewniamy, że co miesiąc będziesz otrzymywał dawkę solidnej wiedzy prosto na swojego maila.